В этом уроке ты
- Научишься оценивать сложность задач с рекурсивными вызовами
- Узнаешь, почему итеративные решения часто лучше рекурсивных
- Поймёшь, откуда берётся stack overflow и как его избежать
Рекурсия

Рекурсия — это способ решения задач, при котором функция вызывает саму себя. Обычно это используется, когда большая задача может быть разделена на несколько меньших, решаемых одинаковым способом.
Главное в рекурсии — правильно определить условие завершения (базовый случай). Если базового случая не будет, рекурсия никогда не закончится.
Факториал
Факториал числа nn!1n5! = 1 * 2 * 3 * 4 * 5
Рекурсивная функция для вычисления факториала:
// Время: O(n)
// Память: O(n)
public class Solution {
public int Factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * Factorial(n - 1);
}
}// Время: O(n)
// Память: O(n)
int factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * factorial(n - 1);
}// Время: O(n)
// Память: O(n)
func factorial(n int) int {
// Условие выхода из рекурсии
if n == 1 {
return 1
}
// Рекурсивный вызов
return n * factorial(n - 1)
}// Время: O(n)
// Память: O(n)
func factorial(n int) int {
// Условие выхода из рекурсии
if n == 1 {
return 1
}
// Рекурсивный вызов
return n * factorial(n - 1)
}// Время: O(n)
// Память: O(n)
import java.util.*;
public class Solution {
public int factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * factorial(n - 1);
}
}# Время: O(n)
# Память: O(n)
def factorial(n: int) -> int:
# Условие выхода из рекурсии
if n == 1:
return 1
# Рекурсивный вызов
return n * factorial(n - 1)- Если
n = 1, функция возвращает 1 (базовый случай). - Если
n > 1, функция вызывает себя с аргументомn - 1и умножает результат наn, пока не дойдёт до базового случая.
Здесь время работы O(n)nO(n)
Облаcти памяти
В контексте исполнения программы чаще всего нас интересуют две основные области памяти:
- Стек (Stack) — область памяти, заранее ограниченная по размеру. В ней хранятся локальные переменные, параметры функций и служебная информация. При рекурсивных вызовах каждый новый вызов «накапливается» в стеке.
- Куча (Heap) — область памяти для динамического выделения. Здесь обычно хранятся объекты, которые передаются по ссылке и могут быть достаточно большими.
В разных языках правила размещения объектов в стеке и куче могут отличаться, но важно понимать, что при рекурсии расходуется стековая память.
Есть структуры данных стек и куча, а есть области памяти с такими же названиями. Важно их не путать!
Про стековую память
Рассмотрим, как растёт стек при вычислении факториала:
// Время: O(n)
// Память: O(n)
public class Solution {
public int Factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * Factorial(n - 1);
}
}// Время: O(n)
// Память: O(n)
int factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * factorial(n - 1);
}// Время: O(n)
// Память: O(n)
func factorial(n int) int {
// Условие выхода из рекурсии
if n == 1 {
return 1
}
// Рекурсивный вызов
return n * factorial(n - 1)
}// Время: O(n)
// Память: O(n)
import java.util.*;
public class Solution {
public int factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * factorial(n - 1);
}
}// Время: O(n)
// Память: O(n)
import java.util.*;
public class Solution {
public int factorial(int n) {
// Условие выхода из рекурсии
if (n == 1) {
return 1;
}
// Рекурсивный вызов
return n * factorial(n - 1);
}
}# Время: O(n)
# Память: O(n)
def factorial(n: int) -> int:
# Условие выхода из рекурсии
if n == 1:
return 1
# Рекурсивный вызов
return n * factorial(n - 1)Если вызвать factorial(4), то при каждом новом вызове factorial(n-1) мы «проваливаемся» вглубь стека. Когда программа достигает базового случая (n=1), происходит «разворот» и вычисление итогового результата.

На глубине, соответствующей n=44factorialn=100100O(n)
Переполнение стека
Если попробовать вычислить факториал для n = 10 000
По умолчанию стековая память невелика (обычно 1–8 МБ), а один вызов рекурсивной функции может занимать около 1 КБ. Поэтому количество возможных рекурсивных вызовов ограничено.
Обычно число рекурсивных вызовов по умолчанию ограничивается примерно 1024. Параметры зависят от ОС, компилятора и других факторов. Нужно помнить, что есть лимит глубины рекурсии, и пользоваться рекурсией с умом.
Что если не стековая память
Если задача требует более 1024 рекурсивных вызовов, есть два варианта:
- Расширить стековую память.
- Переписать рекурсивное решение в итеративное (предпочтительней).
Например, вычисление факториала можно написать итеративно:
// Время: O(n)
// Память: O(1)
public class Solution {
public int Factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}
}// Время: O(n)
// Память: O(1)
int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}// Время: O(n)
// Память: O(1)
func factorial(n int) int {
result := 1
for i := 1; i <= n; i++ {
result *= i
}
return result
}// Время: O(n)
// Память: O(1)
import java.util.*;
public class Solution {
public int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}
}# Время: O(n)
# Память: O(1)
def factorial(n: int) -> int:
result = 1
for i in range(1, n+1):
result *= i
return result// Время: O(n)
// Память: O(1)
export function factorial(n) {
let result = 1;
for (let i = 1; i <= n; i++) {
result *= i;
}
return result;
}Это решение не будет расходовать память под рекурсивные вызовы и гарантированно не «упадёт» из-за переполнения стека.
Фибоначчи
У нас было небольшое отступление, но давай все таки вернемся к рекурсии и более сложным примерами с ней.
Последовательность Фибоначчи — это последовательность чисел, где каждое следующее число равно сумме двух предыдущих, начиная с 010, 1, 1, 2, 3, 5, 8, 13, 21, …
Рекурсивная функция для поиска n-го числа Фибоначчи:
// Время: O(2^n)
// Память: O(n)
public class Solution {
public int Fib(int n) {
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
return Fib(n - 1) + Fib(n - 2);
}
}// Время: O(2^n)
// Память: O(n)
int fib(int n) {
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
return fib(n - 1) + fib(n - 2);
}// Время: O(2^n)
// Память: O(n)
func fib(n int) int {
if n == 0 {
return 0
}
if n == 1 {
return 1
}
return fib(n - 1) + fib(n - 2)
}// Время: O(2^n)
// Память: O(n)
import java.util.*;
public class Solution {
public int fib(int n) {
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
return fib(n - 1) + fib(n - 2);
}
}# Время: O(2^n)
# Память: O(n)
def fib(n: int) -> int:
if n == 0:
return 0
if n == 1:
return 1
return fib(n - 1) + fib(n - 2)// Время: O(2^n)
// Память: O(n)
export function fib(n) {
if (n === 0) {
return 0;
}
if (n === 1) {
return 1;
}
return fib(n - 1) + fib(n - 2);
}Здесь время исполнения получается очень большим (, а память O(2^n))O(n)n
Давай разбираться как так получилось, потому что имея время O(2^n)5 числа Фибоначчи может занять часы!0-ого
Дерево рекурсивных вызовов
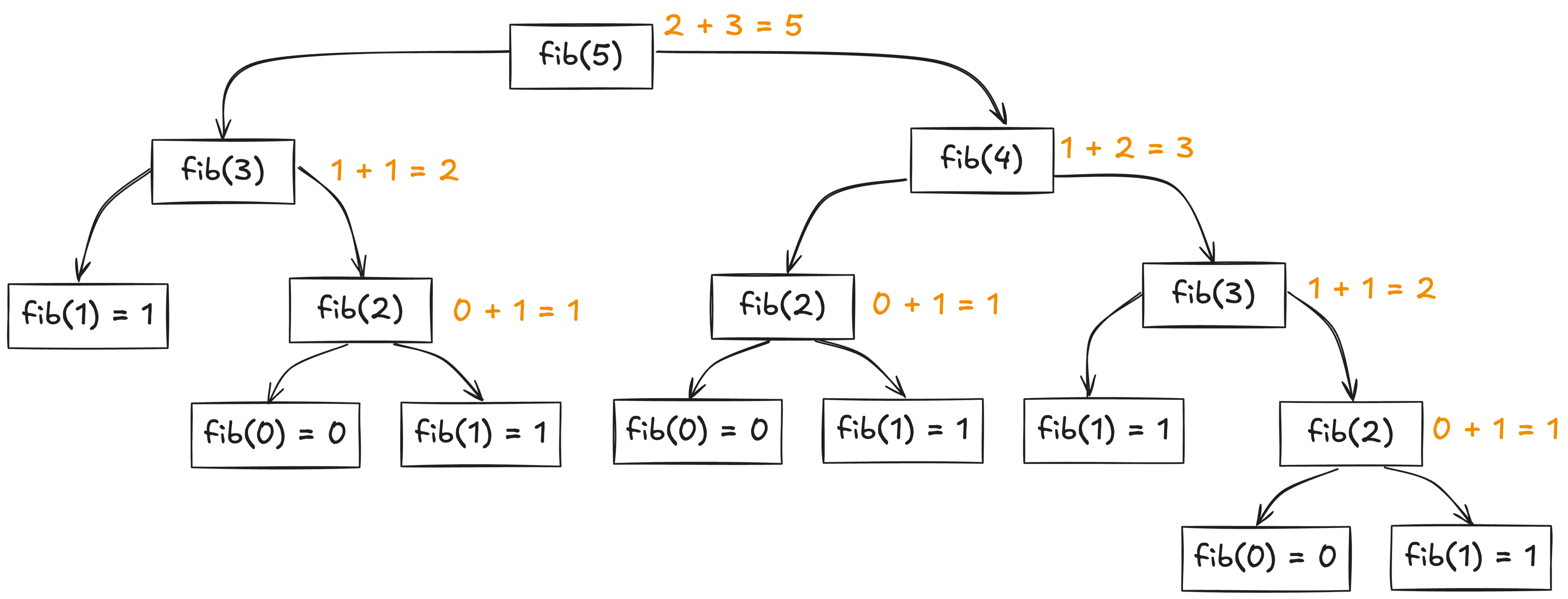
Дерево рекурсивных вызовов — это способ показать, как функции вызывают сами себя.
Для fib(n)fib(2)
В таблице ниже видно, насколько быстро растёт число рекурсивных вызовов:
| Номер числа Фиббоначи | Число рекурсивных вызовов |
|---|---|
| 5 | 15 |
| 10 | 177 |
| 20 | 21891 |
| 30 | 2692537 |
| 50 | …. |
По результатам из таблички можно построить график и наиболее подходящая функция по оценке времени будет 2 в степени n: O(2^n). Мы еще не проходили такую оценку сложности, поэтому тут я сделал оценку за тебя.
O(2^n) редко встречается и такой тип оценок мы будем разбирать отдельно. Чаще всего такая оценка возникает при полном переборе всех вариантов.
Как оптимально искать числа Фибоначчи
Можно использовать итеративный метод:
// Время: O(n)
// Память: O(1)
public class Solution {
public int Fib(int n) {
int a = 0, b = 1;
for (int i = 0; i < n; i++) {
int temp = a;
a = b;
b = temp + b;
}
return a;
}
}// Время: O(n)
// Память: O(1)
int fib(int n) {
int a = 0, b = 1;
for (int i = 0; i < n; i++) {
int temp = a;
a = b;
b = temp + b;
}
return a;
}// Время: O(n)
// Память: O(1)
func fib(n int) int {
a, b := 0, 1
for i := 0; i < n; i++ {
a, b = b, a + b
}
return a
}// Время: O(n)
// Память: O(1)
import java.util.*;
public class Solution {
public int fib(int n) {
int a = 0, b = 1;
for (int i = 0; i < n; i++) {
int temp = a;
a = b;
b = temp + b;
}
return a;
}
}# Время: O(n)
# Память: O(1)
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a// Время: O(n)
// Память: O(1)
export function fib(n) {
let a = 0, b = 1;
for (let i = 0; i < n; i++) {
[a, b] = [b, a + b];
}
return a;
}Здесь нет риска переполнения стека, так как нет вложенных рекурсий, а время работы O(n)
Теперь проблемой станет не время выполнения, а переполнение int-a
Рекурсия на собеседовании
На алгоритмических собеседованиях рекурсию допускают (несмотря на её недостатки) в задачах на графы и деревья, так как итеративные решения в этих темах сложнее в реализации, а время на собеседовании ограничено.
В остальных случаях (особенно на реальной работе) чаще используют итеративные решения, потому что любую рекурсивную программу можно переписать итеративно. Да, иногда это труднее, но это даёт прирост в производительности и возможность работать с большим объемом данных.
Главные выводы
- Рекурсивные вызовы потребляют память (стек), и это нужно учитывать в асимптотической сложности.
- Число рекурсивных вызовов по умолчанию ограничено (часто около 1024). Это можно обойти либо расширением стека, либо переписывая алгоритма в итеративном стиле.
- Рекурсивные решения допустимы, но зачастую неоптимальны, поэтому в большинстве задач выгоднее использовать итеративный подход.