В этом уроке ты
- Узнаешь, зачем нужна хеш-таблица.
- Научишься использовать её в своём языке программирования.
- Поймёшь, как часто хеш-таблица встречается на собеседованиях.
- Разберёшься, какие операции доступны в хеш-таблице и насколько они быстрые.
Как часто хеш-таблица встречается на собеседованиях
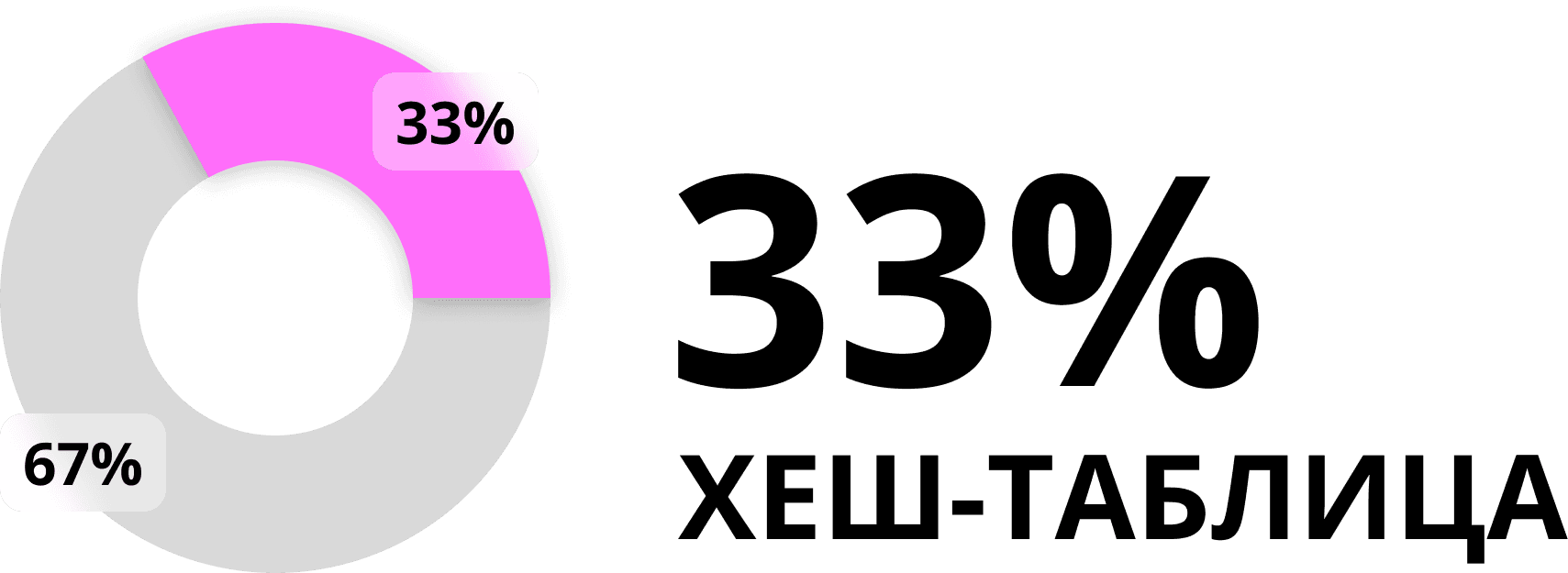
Каждый третий разработчик на собеседовании сталкивается с задачей, где нужна хеш-таблица.
Такой интерес к ней вызван широкой областью применения и эффективностью при решении задач поиска, вставки и удаления.
Кроме практических задач, нередко можно услышать вопрос: «Расскажи, как хеш-таблица работает внутри». Чуть позже мы обязательно вернёмся к этому важному вопросу.
Хеш-таблица в твоём языке программирования
Почти в каждом языке программирования есть встроенные хеш-таблицы. Их объединяет высокая скорость операций, но синтаксис и детали реализации могут отличаться.
Чтобы не растеряться на собеседовании, давай разберём основные операции в твоём языке.
const hashTable = {};
// Вставка/обновление
hashTable[1] = 3;
// Поиск
const val = hashTable[1];
console.log(val);
// Удаление ключа "1"
delete hashTable[1];
// Узнать размер
console.log(Object.keys(hashTable).length);using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
Dictionary<int, int> hashTable = new Dictionary<int, int>();
// Вставка/обновление
hashTable[1] = 3;
// Поиск
int val = hashTable[1];
Console.WriteLine(val);
// Удаление ключа "1"
hashTable.Remove(1);
// Узнать размер
Console.WriteLine(hashTable.Count);
}
}#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<int, int> hashTable;
// Вставка/обновление
hashTable[1] = 3;
// Поиск
int val = hashTable[1];
std::cout << val << std::endl;
// Удаление ключа "1"
hashTable.erase(1);
// Узнать размер
std::cout << hashTable.size() << std::endl;
return 0;
}package main
import (
"fmt"
)
func main() {
hashTable := make(map[int]int)
// Вставка/обновление
hashTable[1] = 3
// Поиск
val := hashTable[1]
fmt.Println(val)
// Удаление ключа "1"
delete(hashTable, 1)
// Узнать размер
fmt.Println(len(hashTable))
}import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<Integer, Integer> hashTable = new HashMap<>();
// Вставка/обновление
hashTable.put(1, 3);
// Поиск
int val = hashTable.get(1);
System.out.println(val);
// Удаление ключа "1"
hashTable.remove(1);
// Узнать размер
System.out.println(hashTable.size());
}
}hash_table = dict()
# Вставка/обновление
hash_table[1] = 3
# Поиск
val = hash_table[1]
print(val)
# Удаление ключа "1"
del hash_table[1]
# Узнать размер
print(len(hash_table))Главное, что нужно знать о хеш-таблице
Поиск в хеш-таблице работает быстро, как и вставка, удаление и получение значений по ключу.
Однако в редких случаях сложность может стать O(n) из-за особенностей реализации. Почему это происходит, разберём позже. Важно запомнить, что в среднем все операции выполняются за O(1):
| Операция | Время (в среднем) | Время (худший случай) |
|---|---|---|
| Вставка | O(1) | O(n) |
| Поиск значения по ключу | O(1) | O(n) |
| Удаление по ключу | O(1) | O(n) |
| Поиск ключа в хеш-таблице | O(1) | O(n) |
| Сделать хеш-таблицу из массива | O(n) | O(n) |
| Сравнение хеш-таблиц | O(n) | O(n) |
Главный вывод: все операции хеш-таблицы в среднем работают за O(1), и именно так их следует оценивать при анализе сложности кода.
Представь, что каждая 100 000-я операция занимает O(n), а остальные 99 999 выполняются за O(1). Это примерная модель, но смысл передаёт хорошо.
Пример задачи с собеседования
Представь, что ты проходишь собеседование. На выполнение первой задачи у тебя есть примерно 20 минут. Вперёд!
Условие
Дан массив целых чисел nums и число target. Нужно вернуть индексы двух чисел из массива nums, которые в сумме дают target. Гарантируется, что есть только один ответ, и индексы должны быть в порядке возрастания.
Пример
Ввод: nums = [1,4,3,-6,2,5], target = -1 Вывод: [3,5] Объяснение: -6 + 5 = -1. "-6" имеет индекс 3, а "5" индекс 5
В чем сложность задачи
Если ты только начинаешь программировать и не решал задач на хеш-таблицы, твоё первое решение может быть неоптимальным:
using System;
class Solution
{
public int[] TwoSum(int[] nums, int target)
{
// Перебираем все возможные пары чисел
for (int i = 0; i < nums.Length; i++)
{
for (int j = i + 1; j < nums.Length; j++)
{
if (nums[i] + nums[j] == target)
{
return new int[] { i, j };
}
}
}
return Array.Empty<int>(); // Возвращаем пустой массив, если пара не найдена
}
}vector<int> twoSum(vector<int>& nums, int target) {
// Перебираем все возможные пары чисел
for (int i = 0; i < nums.size(); i++) {
for (int j = i + 1; j < nums.size(); j++) {
if (nums[i] + nums[j] == target) {
return {i, j};
}
}
}
return {}; // Возвращаем пустой вектор, если пара не найдена
}package main
func twoSum(nums []int, target int) []int {
// Перебираем все возможные пары чисел
for i := 0; i < len(nums); i++ {
for j := i + 1; j < len(nums); j++ {
if nums[i]+nums[j] == target {
return []int{i, j}
}
}
}
return []int{} // Возвращаем пустой срез, если пара не найдена
}import java.util.*;
class Solution {
public int[] twoSum(int[] nums, int target) {
// Перебираем все возможные пары чисел
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] == target) {
return new int[] {i, j};
}
}
}
return new int[0]; // Возвращаем пустой массив, если пара не найдена
}
}# Время: O(n * n), где n — длина массива nums
# Память: O(1)
def two_sum(nums: List[int], target: int) -> List[int]:
# Перебираем все возможные пары чисел
for i in range(len(nums)):
for j in range(i + 1, len(nums)):
if nums[i] + nums[j] == target:
return [i, j]
return []function twoSum(nums, target) {
// Перебираем все возможные пары чисел
for (let i = 0; i < nums.length; i++) {
for (let j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] === target) {
return [i, j];
}
}
}
return []; // Возвращаем пустой массив, если пара не найдена
}Здесь идёт полный перебор всех пар чисел, что занимает O(n²) времени. Это слишком долго для данной задачи, поэтому интервьюер попросит тебя найти более оптимальное решение.
Оптимальное решение
Для оптимального решения используем хеш-таблицу.
using System;
using System.Collections.Generic;
class Solution
{
public int[] TwoSum(int[] nums, int target)
{
// ключ - число, значение - индекс этого числа в массиве
Dictionary<int, int> usedNums = new Dictionary<int, int>();
for (int idx = 0; idx < nums.Length; idx++)
{
int secondNum = nums[idx];
// firstNum - число, которое должно было встретиться ранее,
// чтобы сумма с secondNum дала target
int firstNum = target - secondNum;
// Если firstNum уже встречалось, то возвращаем индексы
if (usedNums.ContainsKey(firstNum))
{
return new int[] { usedNums[firstNum], idx };
}
// Добавляем текущее число в словарь
usedNums[secondNum] = idx;
}
return Array.Empty<int>(); // Возвращаем пустой массив, если пара не найдена
}
}#include <vector>
#include <unordered_map>
using namespace std;
//Время: O(n), где n — размер входного массива.
//Память: O(n), где n — размер входного массива.
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
// ключ - число, значение - на какой позиции встретили число
unordered_map<int, int> usedNums;
for (int idx = 0; idx < nums.size(); ++idx) {
int secondNum = nums[idx];
// firstNum - число, которое должны были встретить раньше
// чтобы текущее число (secondNum) + firstNum дало в сумме target
int firstNum = target - secondNum;
// если firstNum уже встречали в массиве, значит мы нашли
// пару чисел, дающие в сумме target и возвращаем их индексы
if (usedNums.find(firstNum) != usedNums.end()) {
return {usedNums[firstNum], idx};
}
usedNums[secondNum] = idx;
}
return {};
}
};package main
func twoSum(nums []int, target int) []int {
// ключ - число, значение - на какой позиции встретили число
usedNums := make(map[int]int)
for idx, secondNum := range nums {
// firstNum - число, которое должны были встретить раньше
// чтобы текущее число (secondNum) + firstNum дало в сумме target
firstNum := target - secondNum
// если firstNum уже встречали в массиве, значит мы нашли
// пару чисел, дающие в сумме target и возвращаем их индексы
if pos, found := usedNums[firstNum]; found {
return []int{pos, idx}
}
usedNums[secondNum] = idx
}
return []int{}
}import java.util.HashMap;
import java.util.Map;
class Solution {
public int[] twoSum(int[] nums, int target) {
// ключ - число, значение - на какой позиции встретили число
Map<Integer, Integer> usedNums = new HashMap<>();
for (int idx = 0; idx < nums.length; idx++) {
int secondNum = nums[idx];
// firstNum - число, которое должны были встретить раньше
// чтобы текущее число (secondNum) + firstNum дало в сумме target
int firstNum = target - secondNum;
// если firstNum уже встречали в массиве, значит мы нашли
// пару чисел, дающие в сумме target и возвращаем их индексы
if (usedNums.containsKey(firstNum)) {
return new int[]{usedNums.get(firstNum), idx};
}
usedNums.put(secondNum, idx);
}
return new int[]{};
}
}from typing import List
# Время: O(n), где n — длина массива nums
# Память: O(n)
def two_sum(nums: List[int], target: int) -> List[int]:
# Ключ — число, значение — индекс, на котором встретили число
used_nums = {}
for idx, second_num in enumerate(nums):
# first_num — число, которое должно было встретиться ранее
# чтобы second_num + first_num = target
first_num = target - second_num
# Если first_num уже встречали, возвращаем их индексы
if first_num in used_nums:
return [used_nums[first_num], idx]
used_nums[second_num] = idx
return []/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
// ключ - число, значение - на какой позиции встретили число
let usedNums = {};
for (let idx = 0; idx < nums.length; idx++) {
let secondNum = nums[idx];
// firstNum - число, которое должны были встретить раньше
// чтобы текущее число (secondNum) + firstNum дало в сумме target
let firstNum = target - secondNum;
// если firstNum уже встречали в массиве, значит мы нашли
// пару чисел, дающие в сумме target и возвращаем их индексы
if (firstNum in usedNums) {
return [usedNums[firstNum], idx];
}
usedNums[secondNum] = idx;
}
return [];
};Идея в том, чтобы в качестве ключа использовать элемент массива, а в качестве значения — его индекс. Далее надо перебрать все числа в массиве, предполагая, что текущее число — одно из искомых. Второе число определяем как first_num = target - second_num. Если first_num уже есть в хеш-таблице, возвращаем результат. Иначе добавляем текущее число в хеш-таблицу.
Так хеш-таблица хранит числа, которые мы уже прошли, и позволяет быстро проверить, встречали ли мы ранее число, которое в сумме с текущим даёт target.
Зачем нужны массивы, когда есть хеш-таблица
Может показаться, что хеш-таблица идеальна, но у каждой структуры данных свои преимущества.
Например, если нужно часто искать студента по имени, подойдёт хеш-таблица. Но если нужно один раз найти элемент, проще воспользоваться массивом. Построение хеш-таблицы займёт больше времени, чем обычный проход по массиву.
Заключение
На этой лекции мы познакомились с хеш-таблицами, разобрались с принципами их работы и решили задачу с их использованием. Приступай к следующему уроку, чтобы уверенно себя чувствовать на собеседовании и в работе!