В этом уроке ты
- Решишь задачу с собеседования в крупной IT-компании.
- Освоишь методы решения задач на тему «Анаграммы».
- Поймёшь, как выбрать оптимальное решение на собеседовании.
Что такое анаграмма
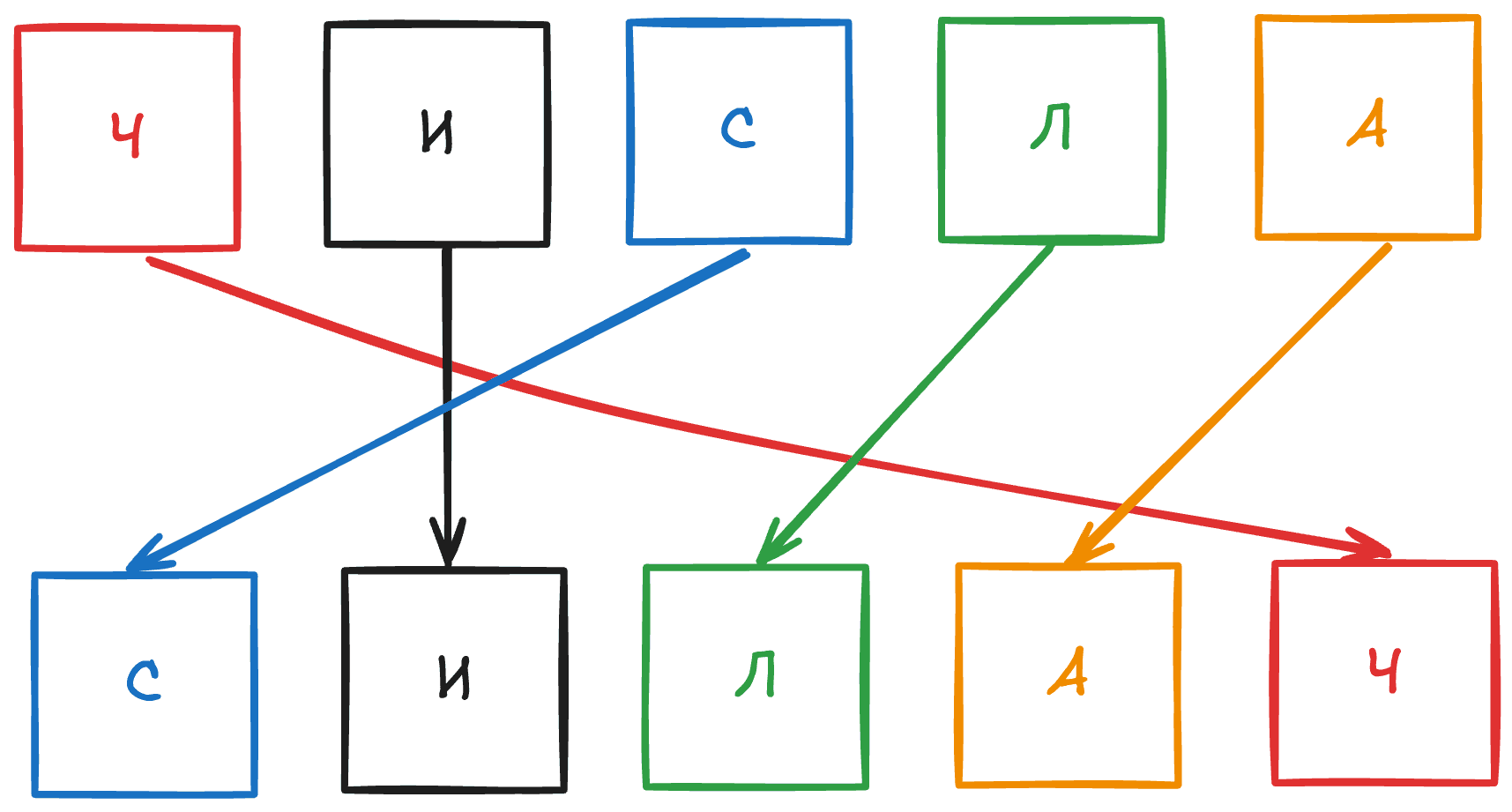
Анаграмма — это слово или фраза, полученные перестановкой букв другого слова или фразы.
Например, «СИЛАЧ» — это анаграмма слова «ЧИСЛА». Переставив буквы в слове «ЧИСЛА», можно получить «СИЛАЧ».
Пример задачи с собеседования
Задачи на анаграммы часто встречаются в начале собеседования, как своего рода разминка. Представь, что у тебя есть 20 минут, чтобы решить следующую задачу.
Условие
Даны две строки s и t. Нужно вернуть True, если t является анаграммой s, и False в противном случае.
Пример 1
Ввод: s = "hello", t = "lolhe" Вывод: true
Пример 2
Ввод: s = "abc", t = "abcc" Вывод: false
В чем сложность задачи
Первое, что может прийти на ум, — отсортировать обе строки и сравнить их:
class Solution
{
public bool IsValidAnagram(string s, string t)
{
// Преобразуем строки в массивы символов, сортируем и сравниваем
char[] sArray = s.ToCharArray();
char[] tArray = t.ToCharArray();
Array.Sort(sArray);
Array.Sort(tArray);
return sArray.SequenceEqual(tArray);
}
}#include <algorithm>
bool isValidAnagram(std::string& s, std::string& t) {
// Cортируем строки и сравниваем их
std::string sortedS = s;
std::string sortedT = t;
std::sort(sortedS.begin(), sortedS.end());
std::sort(sortedT.begin(), sortedT.end());
return sortedS == sortedT;
}package main
import (
"sort"
)
func isValidAnagram(s string, t string) bool {
// Преобразуем строки в массивы рун, сортируем и сравниваем
sArray := []rune(s)
tArray := []rune(t)
sort.Slice(sArray, func(i, j int) bool { return sArray[i] < sArray[j] })
sort.Slice(tArray, func(i, j int) bool { return tArray[i] < tArray[j] })
return string(sArray) == string(tArray)
}package main
import (
"sort"
)
func isValidAnagram(s string, t string) bool {
// Преобразуем строки в массивы рун, сортируем и сравниваем
sArray := []rune(s)
tArray := []rune(t)
sort.Slice(sArray, func(i, j int) bool { return sArray[i] < sArray[j] })
sort.Slice(tArray, func(i, j int) bool { return tArray[i] < tArray[j] })
return string(sArray) == string(tArray)
}import java.util.Arrays;
class Solution {
public boolean isValidAnagram(String s, String t) {
// Преобразуем строки в массивы символов, сортируем и сравниваем
char[] sArray = s.toCharArray();
char[] tArray = t.toCharArray();
Arrays.sort(sArray);
Arrays.sort(tArray);
return Arrays.equals(sArray, tArray);
}
}def is_valid_anagram(s: str, t: str) -> bool:
return sorted(s) == sorted(t)Это работает, но не оптимально. Сортировка занимает O(n*log(n)) времени, а затраты памяти могут варьироваться от O(1) до O(n) в зависимости от реализации.
Интервьюер ожидает более эффективного решения с временем O(n).
Оптимальное решение
Две строки являются анаграммами, если количество каждой буквы совпадает.

Например, в словах «ЛАСКА» и «СКАЛА» содержится:
- 2 буквы «А»
- по 1 букве «С», «К» и «Л»
Мы можем использовать хеш-таблицу (словарь), чтобы подсчитать количество каждой буквы и сравнить эти подсчёты. Это решение работает за O(n)O(n)
public class Solution
{
public static bool IsValidAnagram(string s, string t)
{
if (s.Length != t.Length)
{
return false;
}
var countS = new Dictionary<char, int>();
var countT = new Dictionary<char, int>();
foreach (char c in s)
{
if (!countS.ContainsKey(c))
countS[c] = 0;
countS[c]++;
}
foreach (char c in t)
{
if (!countT.ContainsKey(c))
countT[c] = 0;
countT[c]++;
}
foreach (var kvp in countS)
{
if (!countT.TryGetValue(kvp.Key, out int count) || count != kvp.Value)
{
return false;
}
}
return true;
}
}#include <unordered_map>
#include <string>
using namespace std;
bool isValidAnagram(const string& s, const string& t) {
if (s.length() != t.length()) {
return false;
}
unordered_map<char, int> countS;
unordered_map<char, int> countT;
for (char ch : s) {
countS[ch]++;
}
for (char ch : t) {
countT[ch]++;
}
return countS == countT;
}package main
func isValidAnagram(s string, t string) bool {
if len(s) != len(t) {
return false
}
countS := make(map[rune]int)
countT := make(map[rune]int)
for _, char := range s {
countS[char]++
}
for _, char := range t {
countT[char]++
}
for k, v := range countS {
if countT[k] != v {
return false
}
}
return true
}import java.util.HashMap;
import java.util.Map;
class Solution {
public boolean isValidAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
Map<Character, Integer> countS = new HashMap<>();
Map<Character, Integer> countT = new HashMap<>();
for (char ch : s.toCharArray()) {
countS.put(ch, countS.getOrDefault(ch, 0) + 1);
}
for (char ch : t.toCharArray()) {
countT.put(ch, countT.getOrDefault(ch, 0) + 1);
}
return countS.equals(countT);
}
}def is_valid_anagram(s: str, t: str) -> bool:
if len(s) != len(t):
return False
count_s = {}
count_t = {}
for char in s:
count_s[char] = count_s.get(char, 0) + 1
for char in t:
count_t[char] = count_t.get(char, 0) + 1
return count_s == count_tfunction isValidAnagram(s, t) {
if (s.length !== t.length) {
return false;
}
const countS = new Map();
const countT = new Map();
for (const char of s) {
countS.set(char, (countS.get(char) || 0) + 1);
}
for (const char of t) {
countT.set(char, (countT.get(char) || 0) + 1);
}
for (const [char, count] of countS) {
if (countT.get(char) !== count) {
return false;
}
}
return true;
}Это решение работает за O(n) времени и использует O(n) памяти, что намного оптимальнее предыдущего решения.
Неожиданный вопрос
Хороший интервьюер после решения может спросить: «Можешь решить задачу без словарей, если строки содержат только строчные латинские буквы?»
Да, без переписывания решения тут не обойтись!
Улучшаем решение
Если строки содержат только 26 строчных латинских букв, можно использовать массив фиксированного размера для подсчёта букв.
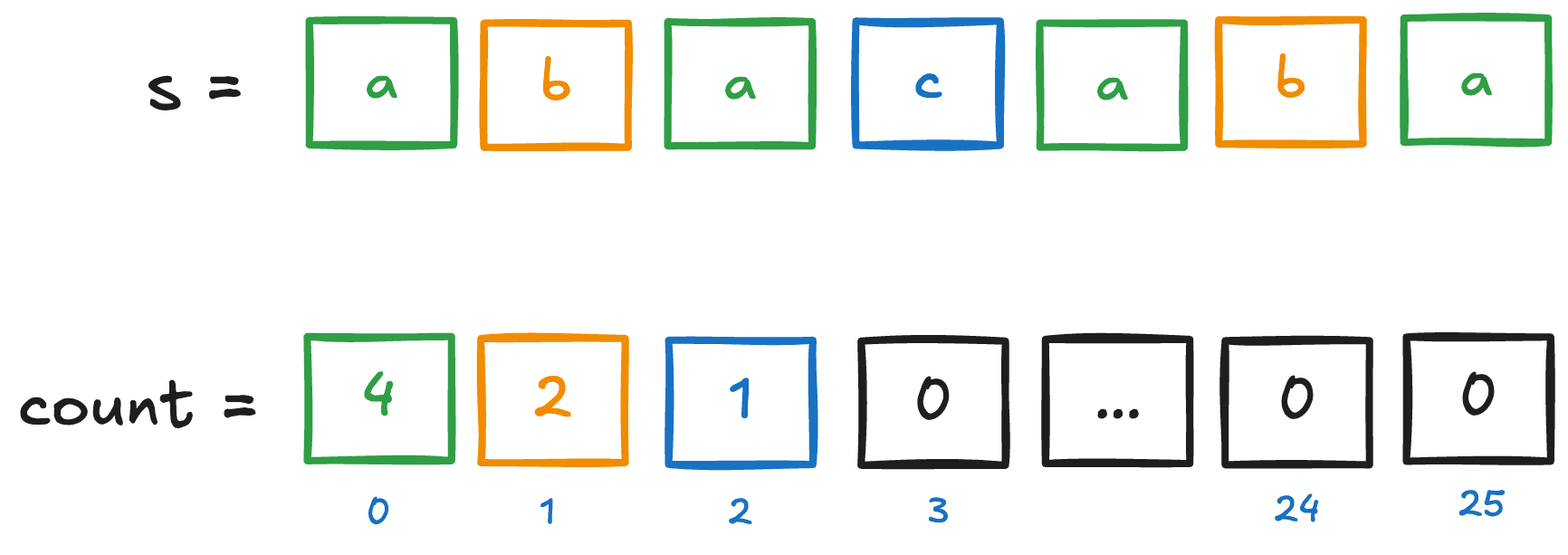
Остаётся понять, как сопоставить букву 'a' с индексом 0 в массиве count, букву 'b' с индексом 1 и т.д. Тут пригодится таблица ASCII.
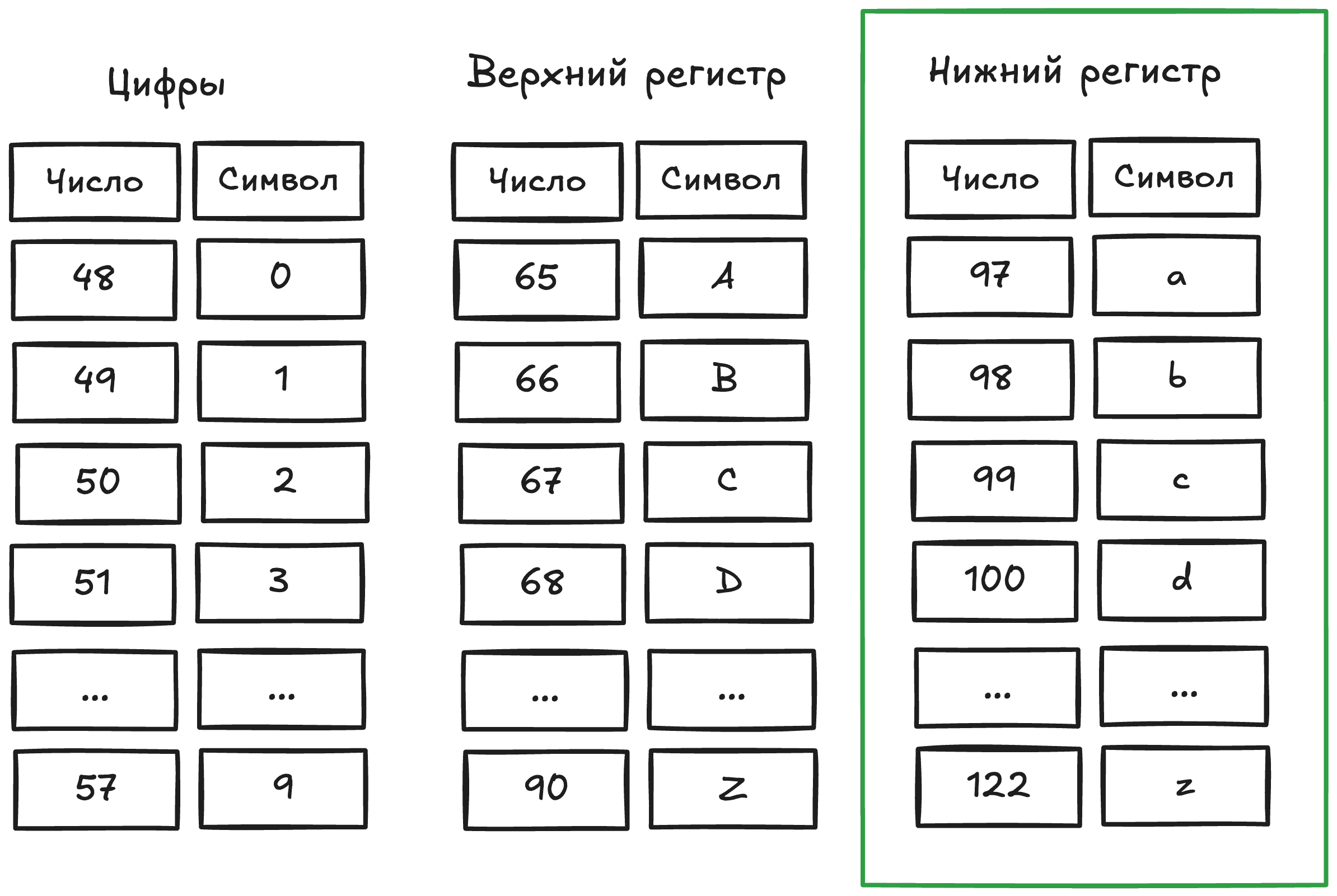
ASCII таблица — это таблица, где каждому символу присвоено числовое значение. Полную таблицу можно найти в интернете, но нас интересует крайний столбец справа.
Значения увеличиваются на 1 от «a» до «z», что как раз нам и нужно для сопоставления буквы с индексом. Теперь осталось разобраться, как из символа получить число и наоборот:
# ord - переводит символ в число
print(ord("a")) # 97
# chr - переводит число в символ
print(chr(97)) # a
class Solution
{
public static bool IsValidAnagram(string s, string t)
{
if (s.Length != t.Length)
{
return false;
}
// Массив для подсчета количества букв (26 символов английского алфавита)
int[] count = new int[26];
// Увеличиваем счетчик для букв из s
foreach (char c in s)
{
count[c - 'a']++;
}
// Уменьшаем счетчик для букв из t
foreach (char c in t)
{
count[c - 'a']--;
}
// Если массив состоит только из нулей, значит строки — анаграммы
foreach (int i in count)
{
if (i != 0)
{
return false;
}
}
return true;
}
}#include <string>
#include <vector>
bool isValidAnagram(std::string &s, std::string &t) {
// индекс - соответствует букве (0 - 'a', 1 - 'b', ...)
// значение - сколько раз встретили букву
std::vector<int> count(26, 0);
for (char c : s) {
// c - 'a' - позволяет перевести 'a' -> 0, 'b' -> 1 и т д
count[c - 'a']++;
}
// уменьшаем число букв, которые встретили проходя по строке t
// делаем это, чтобы не заводить второй массив count.
// Если в самом конце массив получился только из 0 - значит
// все буквы в строках повторяются
for (char c : t) {
count[c - 'a']--;
}
for (int i : count) {
if (i != 0) return false;
}
return true;
}package main
func isValidAnagram(s, t string) bool {
// индекс - соответствует букве (0 - 'a', 1 - 'b', ...)
// значение - сколько раз встретили букву
count := make([]int, 26)
for _, char := range s {
// char - 'a' - позволяет перевести 'a' -> 0, 'b' -> 1 и т д
count[char-'a']++
}
// уменьшаем число букв, которые встретили проходя по строке t
// делаем это, чтобы не заводить второй массив count.
// Если в самом конце массив получился только из 0 - значит
// все буквы в строках повторяются
for _, char := range t {
count[char-'a']--
}
for _, v := range count {
if v != 0 {
return false
}
}
return true
}class Solution {
public static boolean isValidAnagram(String s, String t) {
// индекс - соответствует букве (0 - 'a', 1 - 'b', ...)
// значение - сколько раз встретили букву
int[] count = new int[26];
for (char c : s.toCharArray()) {
// c - 'a' - позволяет перевести 'a' -> 0, 'b' -> 1 и т д
count[c - 'a']++;
}
// уменьшаем число букв, которые встретили проходя по строке t
// делаем это, чтобы не заводить второй массив count.
// Если в самом конце массив получился только из 0 - значит
// все буквы в строках повторяются
for (char c : t.toCharArray()) {
count[c - 'a']--;
}
for (int i : count) {
if (i != 0) return false;
}
return true;
}
}def is_valid_anagram(s: str, t: str) -> bool:
# индекс - соответствует букве (0 - 'a', 1 - 'b', ...)
# значение - сколько раз встретили букву
count = [0 for _ in range(26)]
for char in s:
# ord(char) - ord('a') - позволяет перевести 'a' -> 0, 'b' -> 1 и т д
count[ord(char) - ord('a')] += 1
# уменьшаем число букв, которые встретили проходя по строке t
# делаем это, чтобы не заводить второй массив count.
# Если в самом конце массив получился только из 0 - значит
# все буквы в строках повторяются
for char in t:
count[ord(char) - ord('a')] -= 1
return count == [0 for _ in range(26)]function isValidAnagram(s, t) {
// индекс - соответствует букве (0 - 'a', 1 - 'b', ...)
// значение - сколько раз встретили букву
const count = new Array(26).fill(0);
for (const char of s) {
// char.charCodeAt(0) - 'a'.charCodeAt(0) - позволяет перевести 'a' -> 0, 'b' -> 1 и т д
count[char.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// уменьшаем число букв, которые встретили проходя по строке t
// делаем это, чтобы не заводить второй массив count.
// Если в самом конце массив получился только из 0 - значит
// все буквы в строках повторяются
for (const char of t) {
count[char.charCodeAt(0) - 'a'.charCodeAt(0)]--;
}
return count.every(val => val === 0);
}Алгоритм решения задачи:
- Создаём массив
countдлиной 26 (по числу букв в алфавите). - Индексы в массиве соответствуют буквам (0 для 'a', 1 для 'b' и т.д.).
- Проходим по первой строке и увеличиваем счётчики.
- Проходим по второй строке и уменьшаем счётчики.
- Если все элементы массива равны нулю, строки — анаграммы.
Какое решение выбрать
- Если известно, что строки содержат ограниченный набор символов (например, только строчные латинские буквы), лучше использовать массив.
- Если набор символов неизвестен или велик, словарь будет более универсальным.
Важно спросить интервьюера: «Известно ли, какие символы могут быть в строках?» Это покажет твою внимательность и умение выбирать оптимальное решение до написания кода. Такие вопросы идут только в плюс на собеседовании!
Заключение
Теперь ты знаешь, как эффективно решать задачи на анаграммы и выбирать лучшее решение в зависимости от условий задачи. Скорее переходи к практике, чтобы закрепить знания!