Для оценки нагрузки на сервис частенько используется термин RPS. Он мелькает чуть ли не в каждом разговоре сеньоров, так что давай срочно разберемся что это такое.
RPS (requests per second) — число запросов в секунду, то есть конкретный показатель пропускной способности. Частенько от сеньора можно услышать фразу из разряда: «Смотри, нагрузка на ручку X взлетела до 10 000 RPS». Это значит, что за 1 секунду клиенты сделали запрос к X 10 000 раз (плохо это или хорошо зависит от возможностей системы).
RPS используется для определения нагрузки на сервис. Часто оценивается средний RPS и максимальный RPS — то есть средняя и максимальная нагрузка, которую он может выдержать.
RPS часто применяется в нагрузочном тестировании или бенчмарках. Например: «Мы протестировали наше API, и оно обрабатывает до 10 000 RPS, прежде чем задержка начинает резко расти». Через него удобно сравнивать, как разные архитектуры справляются с увеличением нагрузки.
Почему это важно бизнесу: представьте, что вы занимаетесь агрегатором цветочных магазинов. Максимальную нагрузку нужно знать, чтобы быть готовым к активности покупателей на праздники, иначе проблемы могут начаться в самый неподходящий момент.
Следующий термин — QPS (queries per second)
Он тоже обозначает число запросов в секунду, но уже к базе данных. Так уж сложилось, что под request чаще всего подразумевается обращение к сервису, а вот query — запрос в БД.
Ничего страшного, если ты будешь использовать термин RPS вместо QPS для оценки нагрузки на БД. Главное, в целом знать, что такой показатель есть.
Может быть, тебе будет проще запомнить разницу через внешние и внутренние запросы:
- RPS — клиентские, то есть внешние, запросы за секунду.
- QPS — «внутренние» запросы, например, к базе данных, поисковому движку или другой службе.
Еще несколько терминов проще будет разобрать на примере драматичной истории.
История одного запроса
Представь, что ты реализовал мессенджер и только что его задеплоил. Первое, что ты захочешь сделать — зайти на свой сайт и проверить, всё ли работает.
Ты отправляешь тестовое сообщение ииии… 1 секунда… две… и только сейчас ты его получил. Но почему так долго? Почему пришлось ждать аж две секунды, хотя локально все работало отлично!
Чтобы разобраться, что случилось, давай посмотрим какой путь проходит запрос.
В приложении запрос идет от клиента на сервис, дальше может быть запрос в БД и как результат — пользователь получает ответ.
Чтобы проанализировать, где именно проблема, нужно ее первым делом локализовать, то есть понять, на каком этапе всё тормозиться: проблема долгой отправки может быть связана с долгой доставкой и приемом сообщения или с логикой приложения.
Посмотри, на схеме показываю этапы и временные метрики между ними:
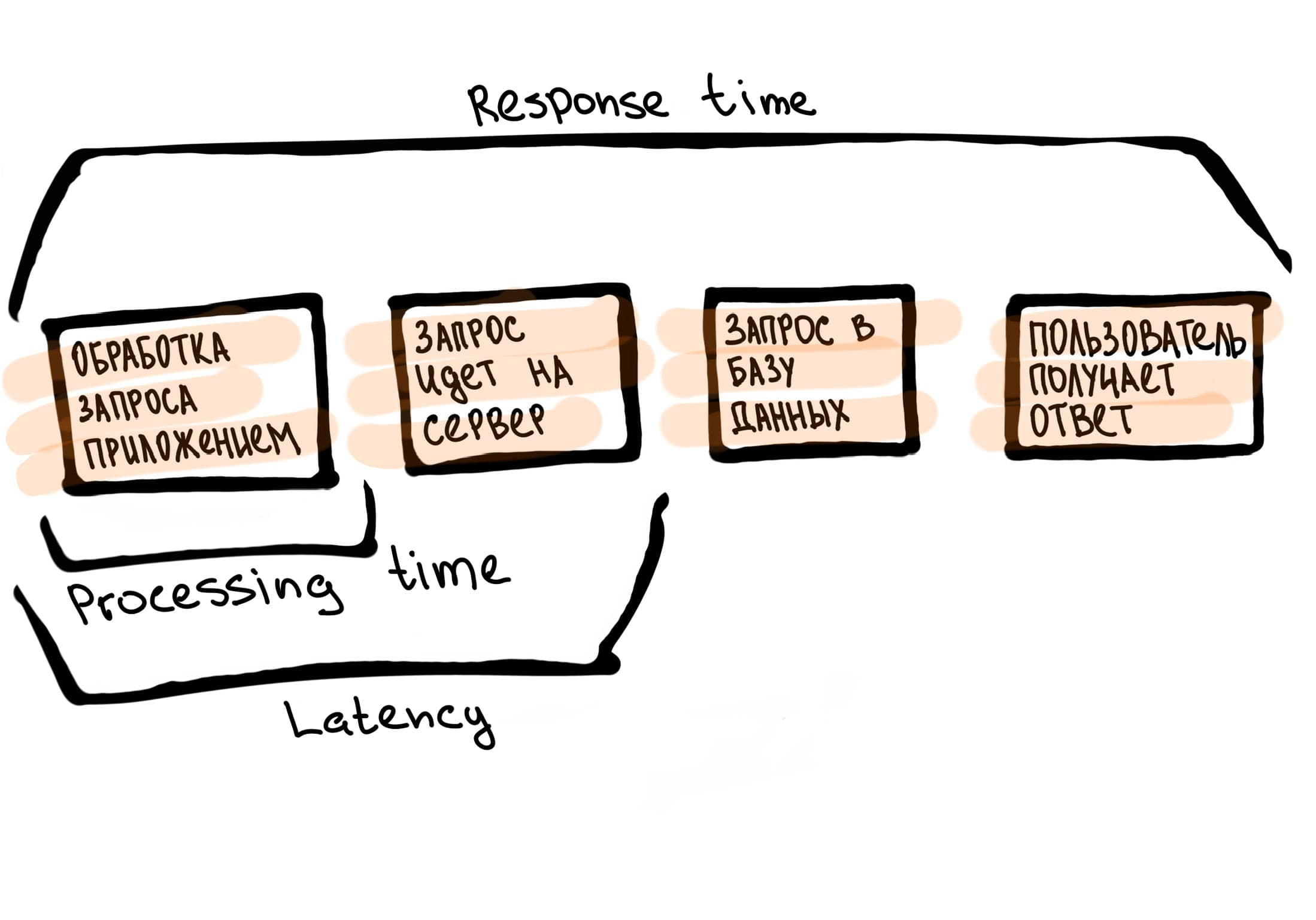
В первую очередь нужно оценить processing time — время обработки запроса приложением.
Если с ним все в порядке, то проблема в latency — время, за которое запрос идет от клиента до сервера. Тут подходит аналогия с письмом, которое пришло в почтовое отделение в нужный город (но дальше с ним пока еще ничего не происходит).
Latency (задержка) критически важна в распределенных системах, когда между клиентом и сервисом значительное физическое расстояние, например, они на разных континентах.
К слову, сейчас мы разбираем на примере запроса от клиента к сервису. Но вообще latency есть у любого запроса, который идет по сети. Например, у запросов от сервиса к базе данных тоже есть метрика latency
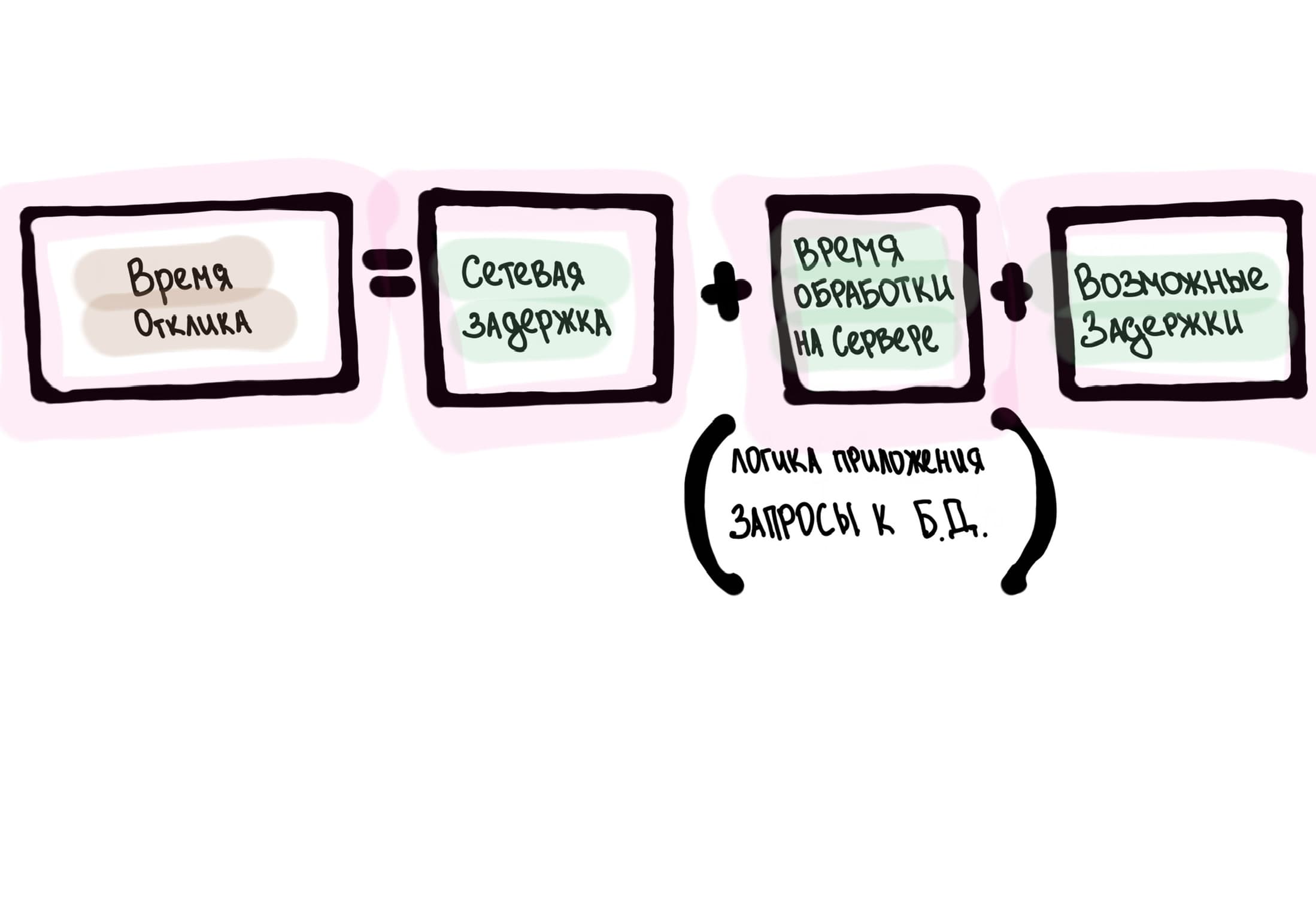
Следующая метрика — время отклика, Response Time. Это общее время с момента, когда клиент инициирует запрос, до момента, когда он полностью получает ответ, то есть весь путь.
Например, если ты отправляешь письмо с формой, которую нужно заполнить, и ждёшь, когда к тебе вернётся заполненный вариант, время отклика — это период с момента отправки до получения заполненной формы обратно.
Время отклика напрямую влияет на пользовательский опыт. Например, если страница загружается 5 секунд, значительная часть этого времени может уходить на саму задержку и выполнение серверной логики.
Чтобы забетонировать различие latency и response time, глянь емкий ответ на StackOverflow из "Кабанчика"
Идем дальше.
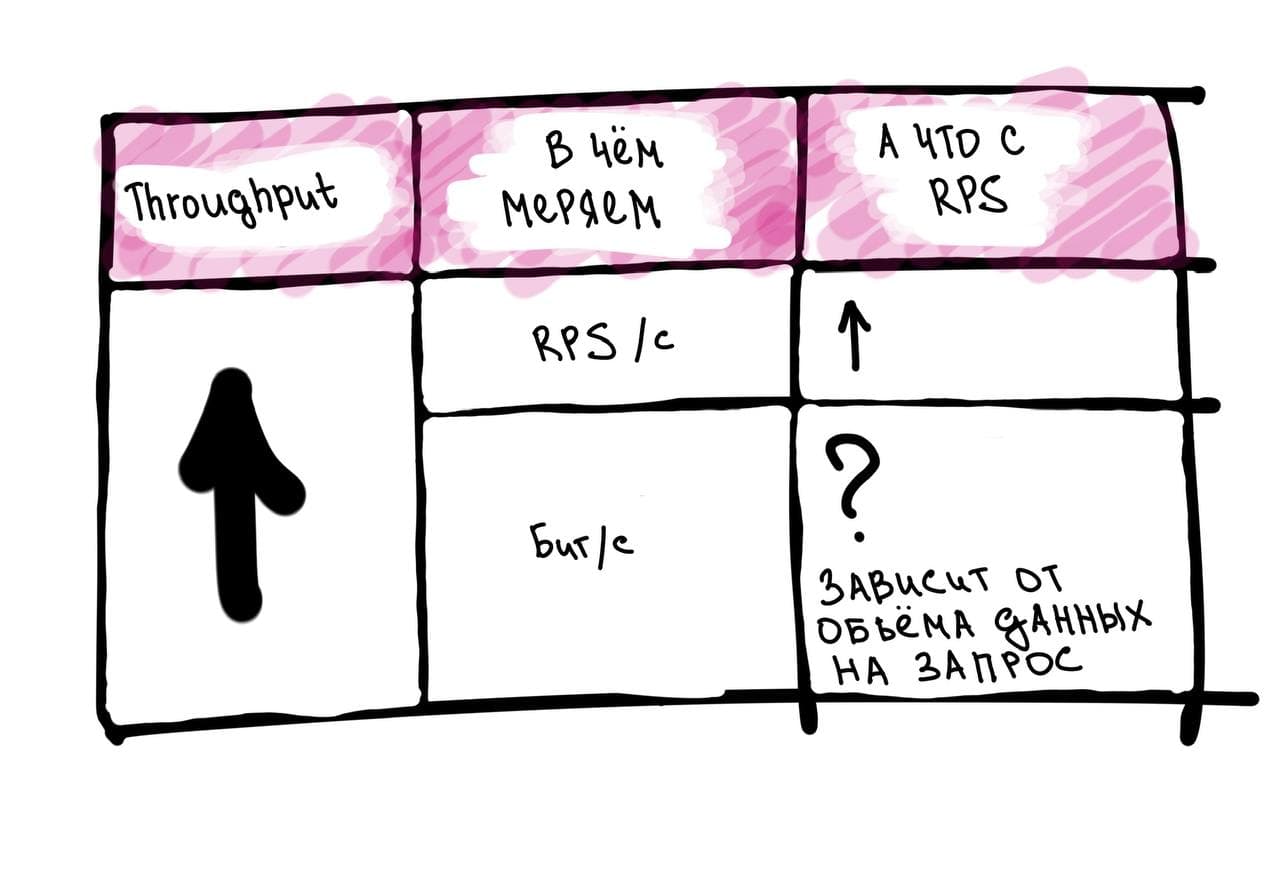
Пропускная способность (Throughput) — показатель, который отражает максимальный объем данных или операций, обрабатываемых системой за единицу времени. Единицы измерения зависят от контекста: это может быть количество запросов в секунду (RPS/QPS), биты в секунду (бит/с), байты в секунду (Б/с), транзакции в секунду (TPS) и так далее.
Помнишь, выше мы говорили про RPS и QPS? Они обозначают количество запросов, а вот пропускная способность — это предельная способность системы по обработке данных или операций.
То есть это разные понятия, но между ними есть взаимосвязь: если пропускная способность измеряется в запросах в секунду, тогда, чем она выше, тем больше запросов система потенциально может обработать. А если она измеряется в данных, например, бит/c, тогда увеличение пропускной способности поможет обрабатывать больше запросов только, если при этом не увеличивается средний объем данных на запрос.
Сравнивать метрики можно только в одинаковых или согласованных единицах!
Пример про однородные единицы: если входящая нагрузка составляет 100 запросов в секунду (RPS), а пропускная способность системы составляет 150 запросов в секунду (max RPS), значит, система по этому параметру справляется.
Пример про согласованные метрики: если входящий RPS = 100 запр/сек, а пропускная способность системы ограничена сетью и составляет 100 Мбит/сек, нужно проверить средний размер запроса.
Допустим, средний запрос передает 1 Мбит данных. Тогда требуемая пропускная способность = 100 запр/сек * 1 Мбит/запрос = 100 Мбит/сек. В этом случае система справляется ровно на пределе. Если средний размер запроса вырастет до 1.1 Мбит, то требуемая пропускная способность (110 Мбит/сек) превысит фактическую (100 Мбит/сек).
Когда throughput системы (в битах/сек) меньше, чем требуется для обработки входящих запросов (рассчитывается это как Входящий RPS * Средний размер запроса в битах), нужна оптимизация. Иначе запросы будут вставать в очередь, и клиент будет дольше ожидать ответа от системы, а это ухудшает UX.
Оптимизация это, например, сжатие данных, чтобы уменьшить средний размер запроса, или кэширование, чтобы уменьшить число запросов. Или масштабирование — про него будем много говорить чуть позже.
Давай небольшой блиц, как все эти термины связаны и чем отличаются друг от друга.
Задержка vs время отклика
Задержка — это лишь часть общего времени отклика. Время отклика включает время обработки на сервере, а также любые дополнительные задержки (например, в очередях) и сетевое время туда-обратно.
Время отклика vs пропускная способность
Высокая пропускная способность может влиять на время отклика — при росте числа одновременных запросов (увеличением RPS) на сервере могут скапливаться очереди, и это итоге повышает время отклика.
Такое бывает, если система не масштабирована должным образом. При грамотном масштабировании пропускная способность остается высокой, так что удаётся сохранять низкое время отклика.
Высокий RPS ≠ высокая производительность
Если RPS высокий, это означает, что система обрабатывает много запросов в секунду, но при этом запросы могут быть «легкими» (например, статический контент) и не нагружать систему. Так что хвастаться тут пока что нечем.
А высокий RPS при большой задержке (latency) — это точно плохо, потому что это означает, что большое количество пользователей ждут ответа.
УФ, надеюсь, что после блица стало понятнее.