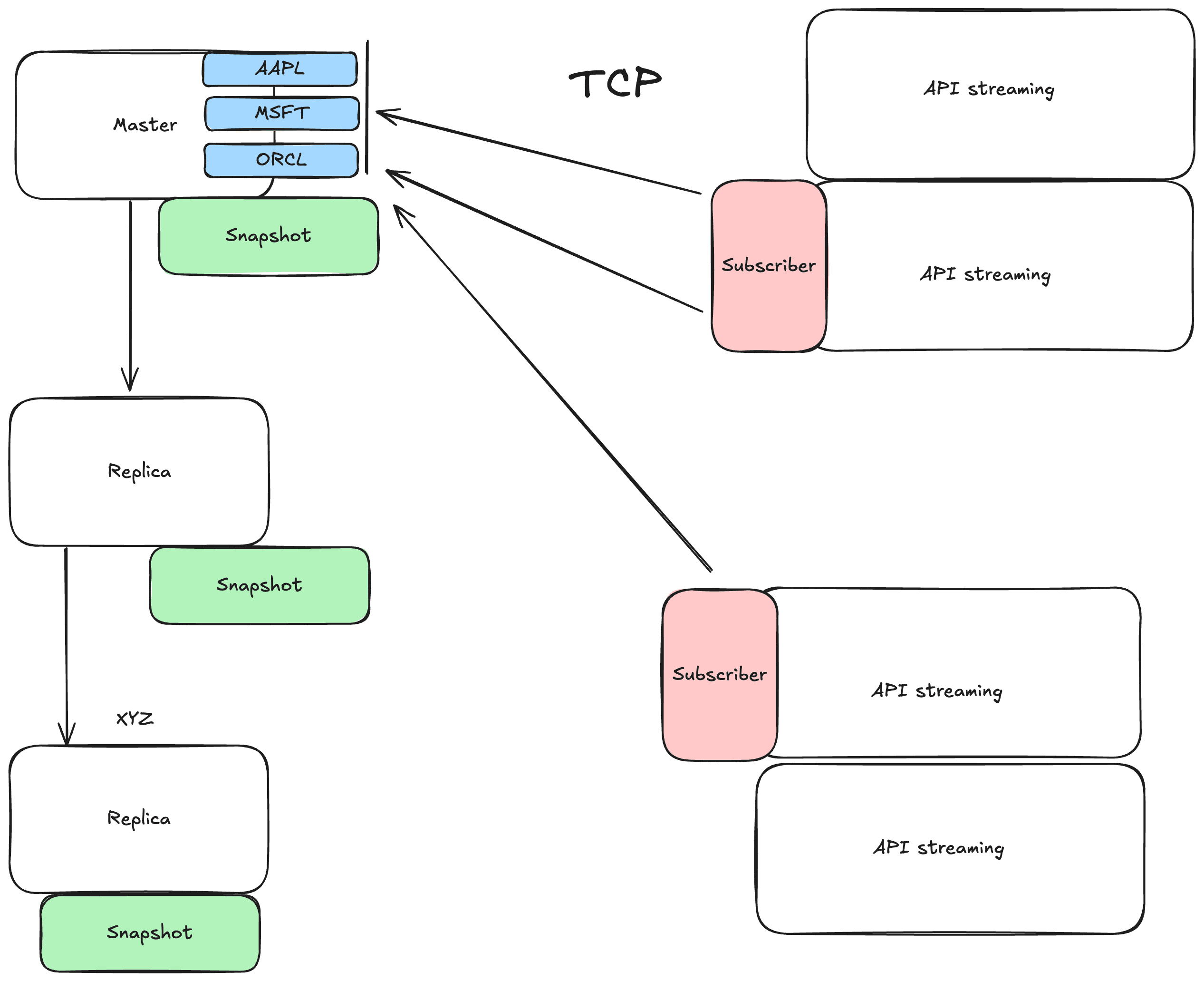
Нам нужно решение для агрегации tickers с минимальной задержкой. Будем использовать решение Redis Pub/Sub (альтернативы разберем далее в этом блоке).
- Важно: на самом интервью можешь не говорить, что обязательно Redis Pub/Sub, а скорее концепцию из данной технологии. Так как часто в Big Tech либо делают свои решению, либо дорабатывают имеющиеся. Это избавит тебя от дополнительных вопросов “А точно ли так можно делать в Redis”
Важно: когда ты говоришь “Мы сделаем 10 шардов, 15 реплик” - нужно объяснение данного решения. Без объяснения это выглядит непрофессионально.
Конфигурация:
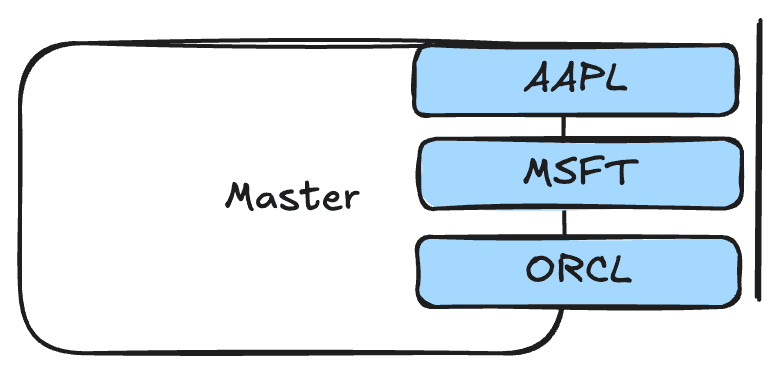
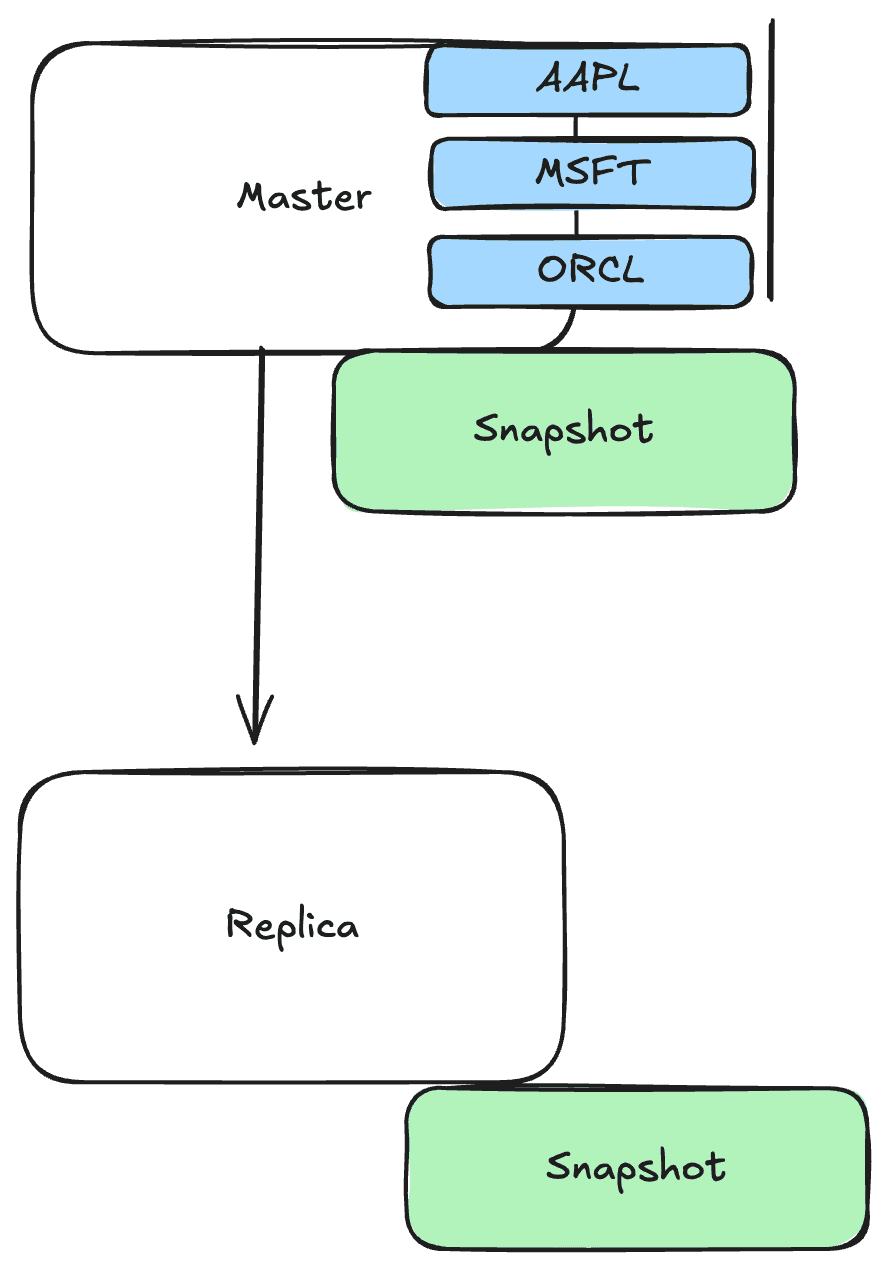
- Используем одну ноду для записи и чтения с нее. В рамках этой ноды Redis сделает логические очереди для subscribers (так как каждый клиент подписан на разные tickers). По сути это аналог topic в Kafka.
- В то же время делаем async replication на наши другие ноды. Из-за частого обновления тикеров даже если будет какая-то потеря, то не критично.
- Как вариант, можно обсудить semi-sync вариант репликации
- В случае отказа основного инстанса Redis Sentinel (watchdog, который мониторит состояние Redis) делает failover на более подходящую реплику
- Для redundancy нам нужно поставить доп реплики
- Сразу возникает вопрос: а если не будем держать нагрузку по connections к Redis инстансу?
- Более валидные варианты:
- Провести load testing и понять реальное ограничение. До определенного уровня вертикальное масштабирование может помочь.
- Вообще поменять решение с Redis Pub/Sub на Kafka (разберем в отдельном блоке про падение Redis).
- Менее валидные варианты:
- Возможен вариант с вычитки из реплик, но есть риск потери данных и задержек.
- Можно на уровне publisher сразу писать в несколько реплик (то есть данные будут консистентны) и держать больше нагрузки. Но тут сразу момент с отслеживанием конфликтов между репликами.
- Более валидные варианты:
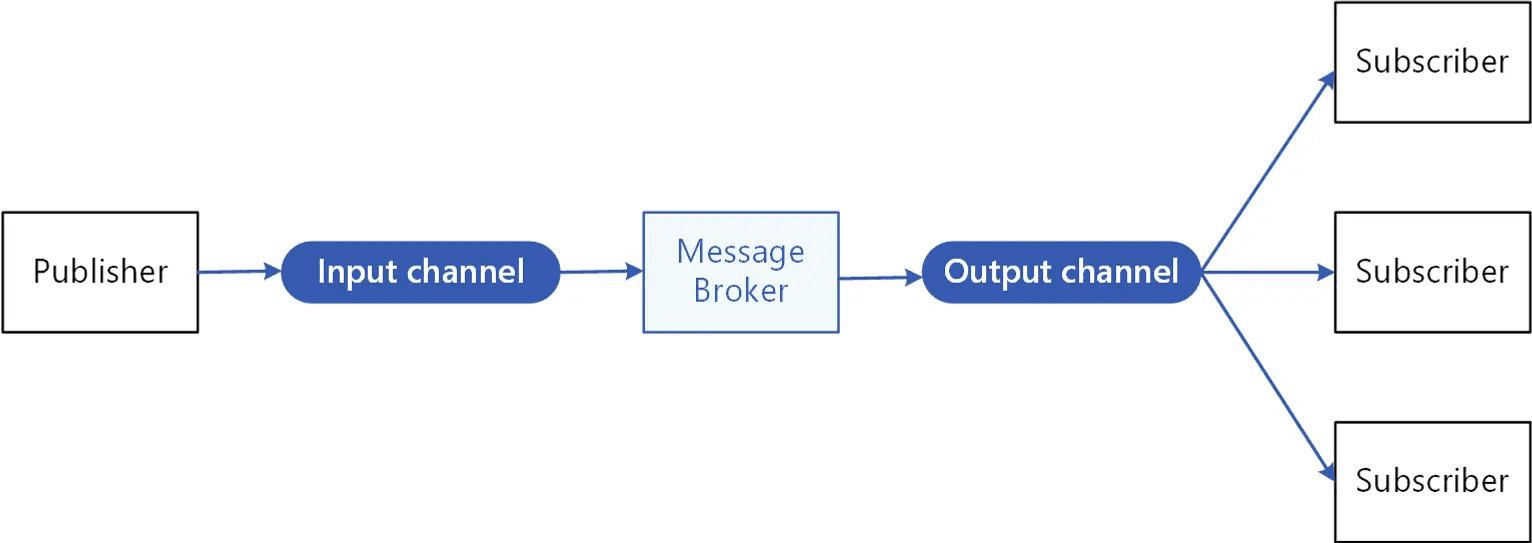
Механизм Pub/Sub:
Redis используется для подписки стриминговых API на обновления в реальном времени, что позволяет эффективно рассылать изменения клиентам.
State
Redis будет хранить state, чтобы сразу выдавать последнюю инфу для клиентов, которые были не в онлайне, а потом подключились. То есть при подключении клиента происходит вычитка по нужным ключам. А далее клиент уже начинает слушать очередь и получать новые данные.

В Redis используется термин snapshot, поэтому далее будем указывать этот термин. Но помни, что это “снимок” данных на какой-то момент времени и мы будем его обновлять время от времени.
Даже если клиент долго не был подключен, то snapshot будет всегда обновляться и клиент получит свежие данные.
Как система понимает, что сначала нужно отдать snapshot, а уже потом поключиться слушать очередь?
- Стриминг сервис получает от клиента список тикеров
- Далее он сходит в Redis за snapshot
- А уже потом подписка на прослушивание очереди
| Сценарий | Как система работает |
|---|---|
| Клиент подключён и слушает Pub/Sub | Получает все новые обновления в реальном времени |
| Клиент не подключён в момент публикации | Пропускает эти события |
| Клиент подключается заново | Получает snapshot из Redis (актуальные данные) и затем подписывается на Pub/Sub для новых обновлений |
Почему именно Pub/Sub + snapshot, а не полноценная Kafka/RabbitMQ?
| Критерий | Redis Pub/Sub + Snapshot | Kafka / RabbitMQ |
|---|---|---|
| Гарантия доставки | Нет гарантии: если подписчик не подключён, сообщение теряется | Kafka/RabbitMQ сохраняют сообщения, можно получить позже |
| Персистентность | Нет хранения сообщений, только актуальное состояние в Redis | Сообщения хранятся на диске, можно настраивать срок хранения |
| Задержка (latency) | Минимальная, ultra-low latency | Kafka — низкая, но чуть выше из-за записи на диск; RabbitMQ — низкая |
| Надёжность при сбоях | Возможна потеря сообщений при падении/отключении | Сообщения не теряются, можно восстановить после сбоя |
| Использование памяти | Всё в памяти, быстро, но ограничено объёмом RAM | Kafka/RabbitMQ используют диск, могут работать с большими объёмами |
| Поддержка snapshot | Нужно реализовывать отдельно | В Kafka можно читать с любого offset, реализуя snapshot/историю |
Когда Redis Pub/Sub + snapshot лучше?
- Минимальная задержка критична (например, для мгновенной реакции на изменение котировки).
- Можно мириться с потерей данных (например, если важна только последняя цена, а не вся история изменений).
Когда Kafka или RabbitMQ лучше?
- Нельзя терять сообщения — критична гарантия доставки (например, для финансовых транзакций, аудита, аналитики).
- Нужна история изменений — клиенты могут читать не только последние данные, но и всю последовательность событий.
- Возможна временная недоступность клиентов — сообщения сохраняются и могут быть доставлены позже.
А как мы будем хранить snapshot?
- Он будет храниться на каждой реплике
- При подключении клиента в онлайн Redis вытащит snapshot из БД
Итого