А что если наш кластер Redis упадет? Это будет означать конец для всей системы.
Существует много вариантов, как сделать данное решение более надежным.
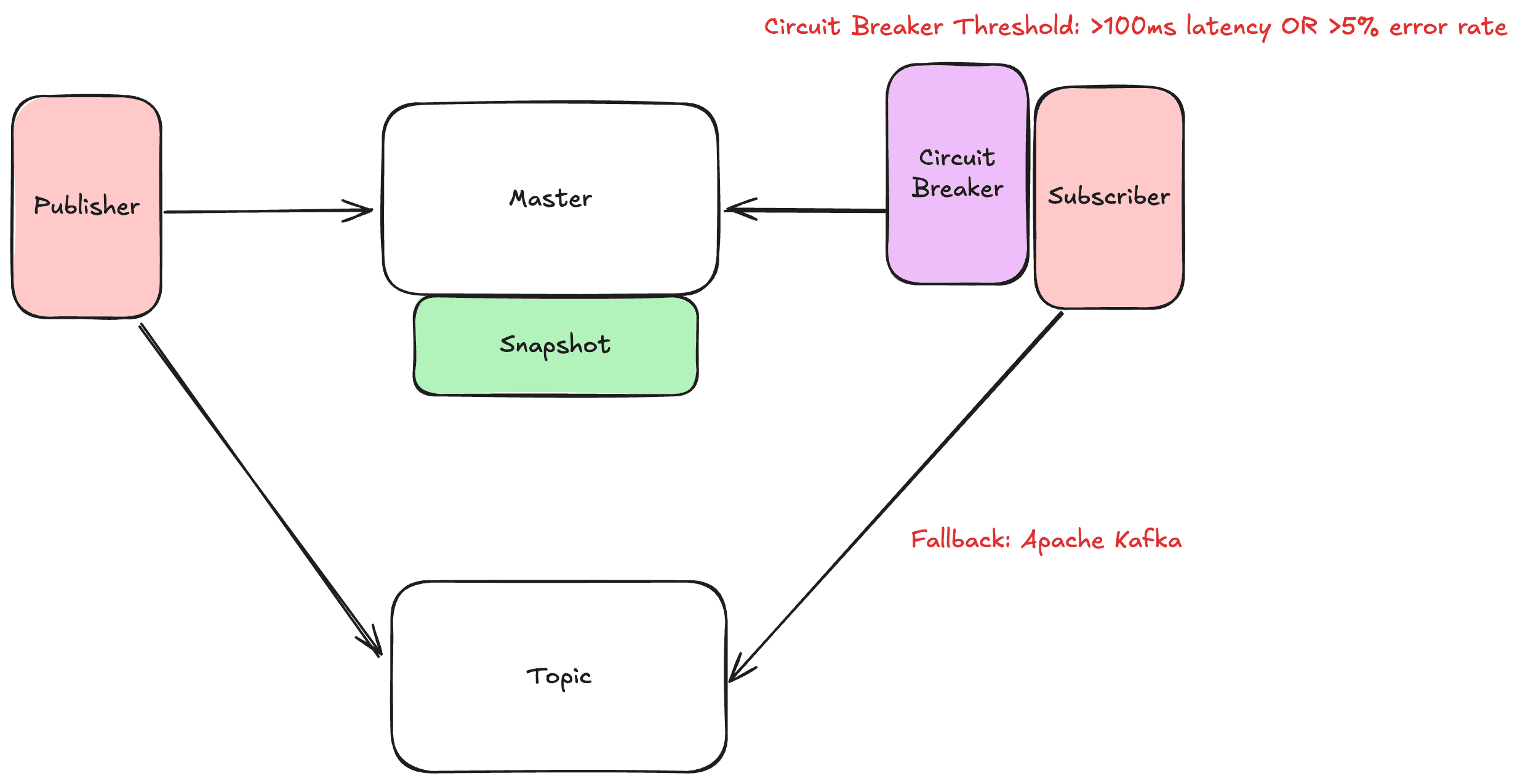
💡В примерах ниже везде будет circuit breaker, который активируется если от Redis пришло n ошибок за m времени.
💡Подход для обработки ошибок называется fallback: это может быть как выброс exception клиенту, так и переход на запасной вариант обработки
💡Подход, когда мы не сразу падаем в случае отказа какого-то модуля, а пытаемся сделать это незаметно для клиента или с минимальными проблемами — graceful degradation
Спорный вариант:
- Вообще не использовать Redis и заменить на Kafka. Но тут нужно думать про а) Пропускную способность (так как у нас ultra low latency) б) Удаление данных, так как поток tickers очень большой. То есть вариант с Kafka потребует очень тонкой настройки.
Рабочие варианты:
- Поставить Kafka рядом. Запись будет идти как в Redis, так и в Kafka.
- Если включается circuit breaker, то начинаем читать из Kafka. Это медленнее, но зато получаем хоть какой-то поток данных. Плюс Kafka можно оптимизировать для более быстрой вычитки.
- Также есть риск, что запишем данные в redis, а в Kafka не запишем (ошибки сети, упал broker). Можно подумать про transactional outbox.
В общем такой подход называется Dual Message Broker Pattern. В данном случае система мониторит latency или кол-во ошибок от Redis. Если какое-то из условий выполняется, то делается fallback на Kafka.
Также можно слать event Клиентам, что у нас проблемы, поэтому доставка данных будет чуть дольше.
2. Поставить еще один Redis, в которых переливать данные регулярно. Если отрубается основной кластер, то идем на запасной
- В данном случае будет больше нагрузка на основной кластер, так как будет репликация
- Доп расходы по обеспечению кластера
- То есть можно настроить след механизмы и переливать их с одного кластера на другой
- RDB (snapshotting): периодически сохраняет полную копию данных на диск
dump.rdb - AOF (Append-Only File): логирует каждую команду изменения данных, чтобы можно было восстановить состояние после сбоя
- RDB (snapshotting): периодически сохраняет полную копию данных на диск