Клиент ищет точки на карте
- Сначала идет поиск ближайших заведений через Geo Service. Данный сервис возвращает ID заведений
- Далее идет запрос в Places Service, чтобы вытащить данные о заведении (карточка)
- API Composition Pattern: шлюз получает ID от Geo Service, далее идет в Places Service, чтобы вытащить всю информацию.
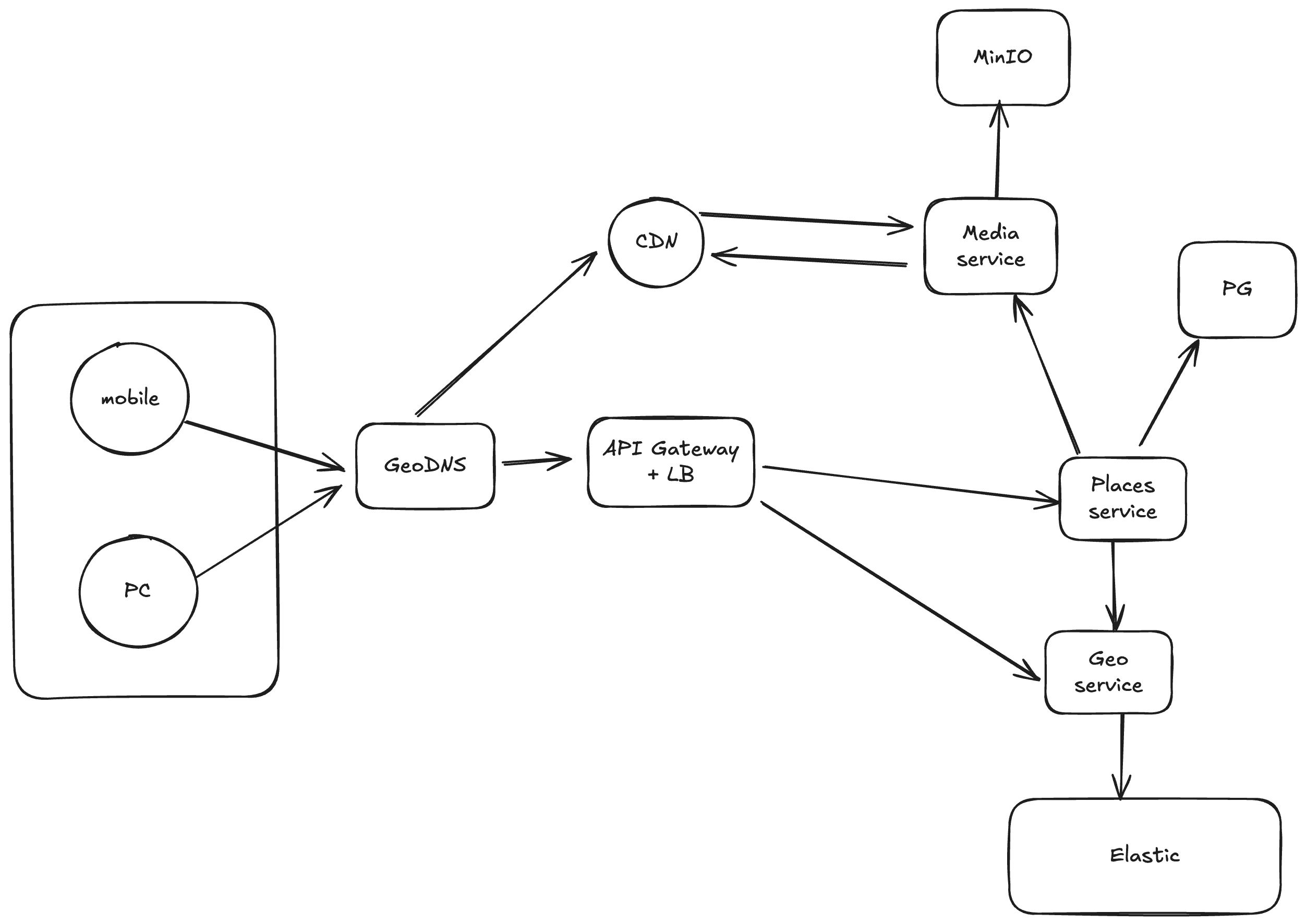
Почему не хранить всю инфу о заведениях в одном сервисе?
- Позволяет разделить на 2 команды разработки
- Проще делать deploy системы
- Разные модели данных
- Places работает сугубо со структурой заведений (карточка)
- Geo же занимается работой с геопространством
- Single Responsibility Principle и Separation of Concerns — подход микросервисоной архитектуры
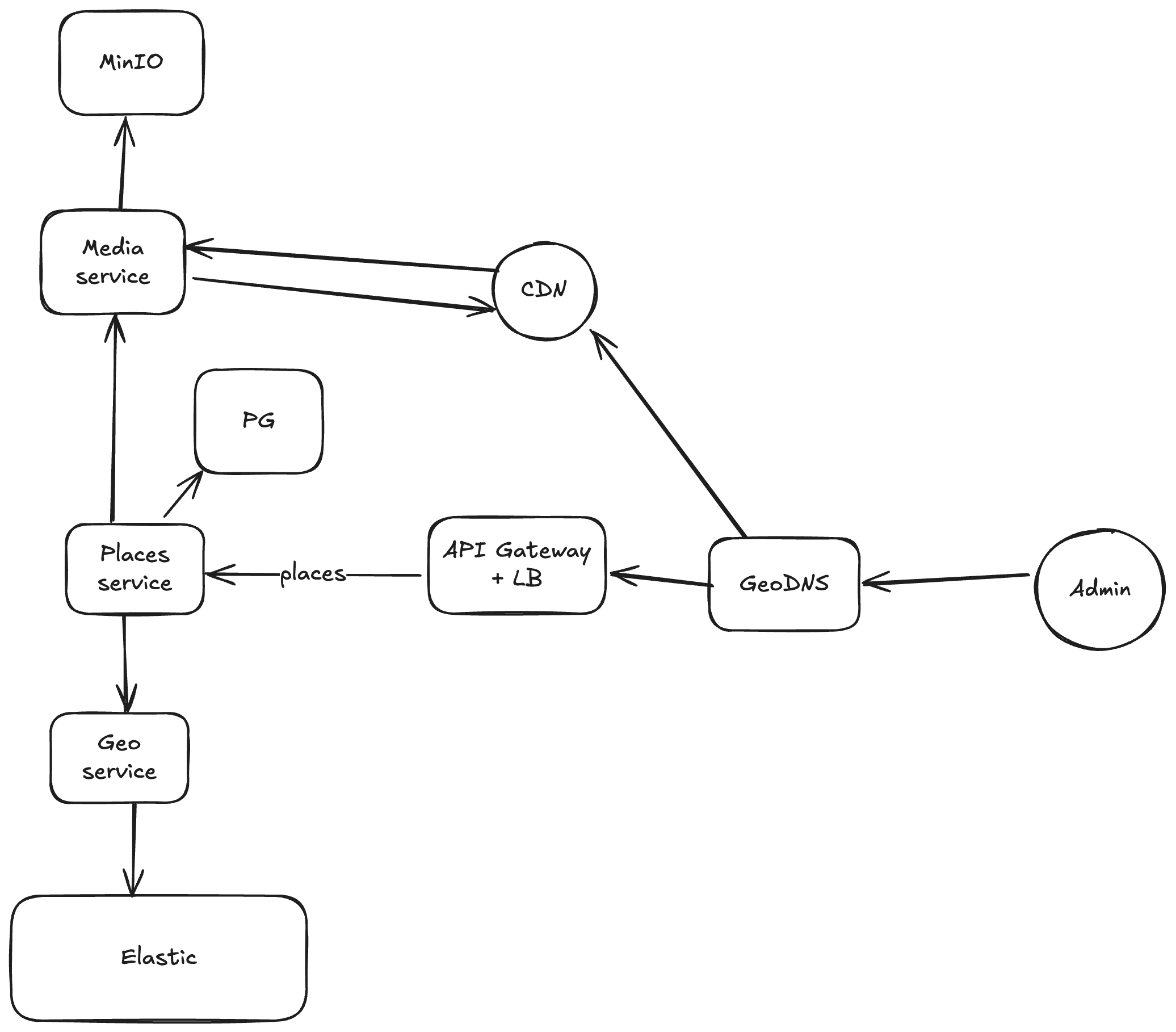
Создание заведения
- Admin вносит данные
- Places прихранивает их в PG
- Делает запрос в GeoService, чтобы добавить в поиск новое заведение
- Kafka между Places & Geo Services
- После того, как вносится изменение в Places сервис, публикуется event в Topic
- Далее этот event вычитывается на стороне places и обновляется локация
- eventual consistency между внесением изменений в место и тем, как клиент увидит обновленную инфу
- Places кладет статику в Media Service. А он уже в MinIO
- Далее Media Service уже сам работает с CDN
Как можно оптимизировать работу с Blob Storage?
В нашей системе админ загружает картинки заведений вместе с остальной инфой. Проблема данного решения - нам через нашу систему нужно перегонять все данные. Какая есть альтернатива - использовать pre-sign URL и event от S3.
- Админ загружает основную инфу на backend
- Backend отдает pre-sign URL
- Админ напрямую грузит данные blob storage
- От blob storage идет event до media storage, который делает доп обработку медиа-контента
Можешь почитать про это здесь: https://fourtheorem.com/the-illustrated-guide-to-s3-pre-signed-urls/