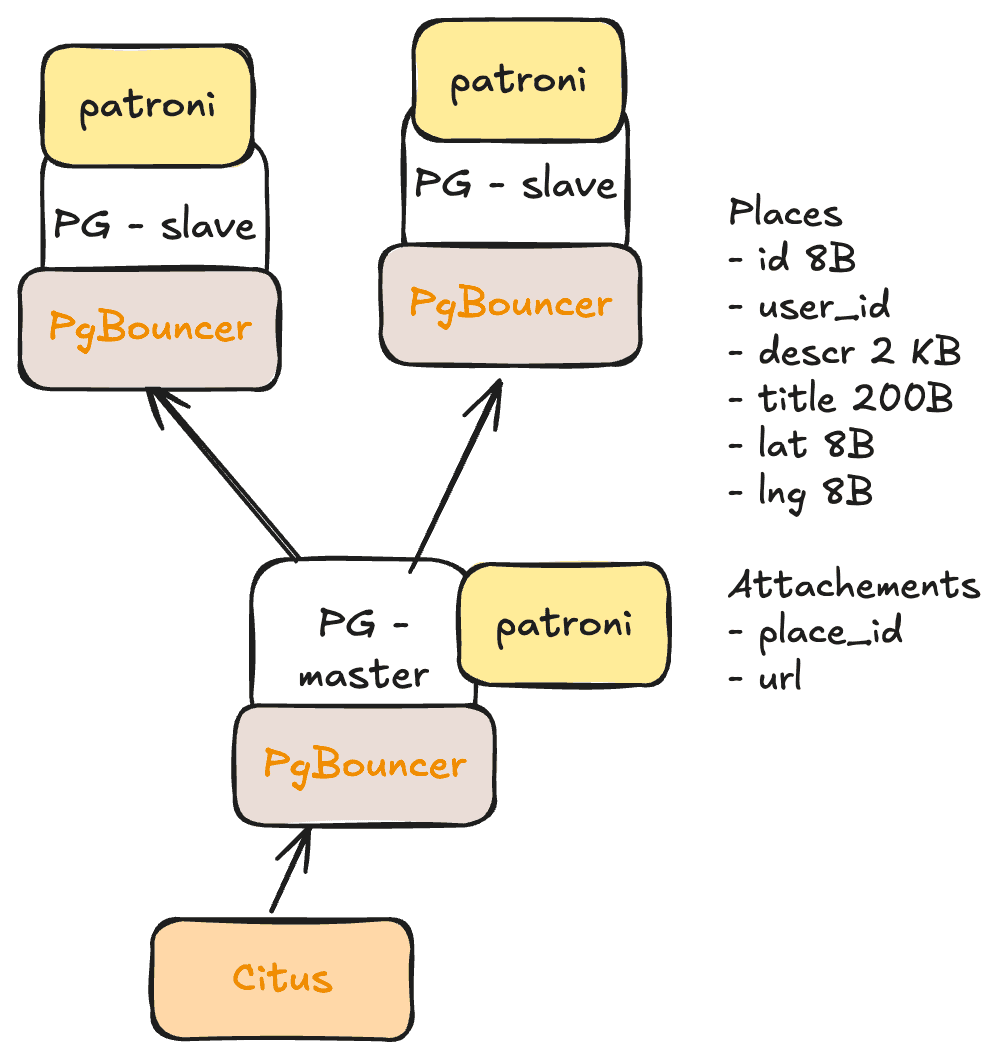
Схема
Places - id - user_id - descr - title - lat - lng Attachements - place_id - url
❗В нашей системе объем данных не супер большой и по факту нам можно обойтись master-slave без доп усложнений. Но давай представим, что объем данных в разы больше - храним TB & PB, чтобы ты понимал, а как можно работать с таким объемом данных.
- RF (replication factor) 2 как минимум, чтобы обеспечить надежность системы.
- Делаем sync replication, чтобы не потерять данные, если будет failover
- PgBouncers для write & read реплик
- Citus для PG sharding
- Сам распределяет при записи и собирает при чтении
- Позволяет делать ACID (distributed transactions)
- Automatic rebalancing: если нужно изменить формат шардирования, то Citus сам перельет данные
- Failover с master на slave: Для этого можно использовать готовое решение. Например, Patroni
- автоматизация failover
- leader election
- cluster management
- automatic recover: если какая-то node упала
- Важно: у данного механизма нет leader node. Все работает на модели распределенного консенсуса
Для ключа шардирования берем place_id.
Но почему не учитываем локацию?
- Hot spots: популярные районы (центры городов) создают unbalanced shards
- Uneven distribution: различная плотность заведений по городам
❓Почитать больше о Patroni (нужен для failover): https://dev.to/prezaei/high-availability-postgresql-clustering-with-patroni-5043
✅Если хочется копнуть глубже в HA Postgres, то рекомендую почитать:
- Google Cloud про HA PG: https://cloud.google.com/architecture/architectures-high-availability-postgresql-clusters-compute-engine
- Как достичь HA PG: https://www.yugabyte.com/postgresql/postgresql-high-availability/
- Как делать failover с Patroni: https://www.enterprisedb.com/node/1263721