TLDR какой сетап:
GeoHash для оптимизации работы кеша
- Подход: Cache-aside + Write-around
- Замещение: LRU
- Инвалидация:
- 2 уровня TTL (для более больших и для более маленьких локаций)
- event-based
GeoHash - способ представления координат как string. Чем длиньше string тем более точная будет локация dr5r - 1.5km dr5re - 150m dr5reg - 30m ... Например, берем lat & lon: 40.7432, 57.3213 => dr5reg Далее мы можем показать ближайшие заведения: dr5regu, dr5regv, dr5regw
Для простоты реализации заиспользуем Redis, так как в нем есть встроенный GeoHash:
# Добавление заведения в геоиндекс GEOADD places:index 13.361389 38.115556 "place:123" # Поиск в радиусе с кэшированием результата GEORADIUS places:index 13.361389 38.115556 1 km WITHCOORD WITHDIST
Как это выглядит на схеме:
Инвалидация
Также данный подход помогает настраивать более точечный TTL:
- Более крупные области имеют более долгий TTL
- Более мелкие области имеют более короткий TTL
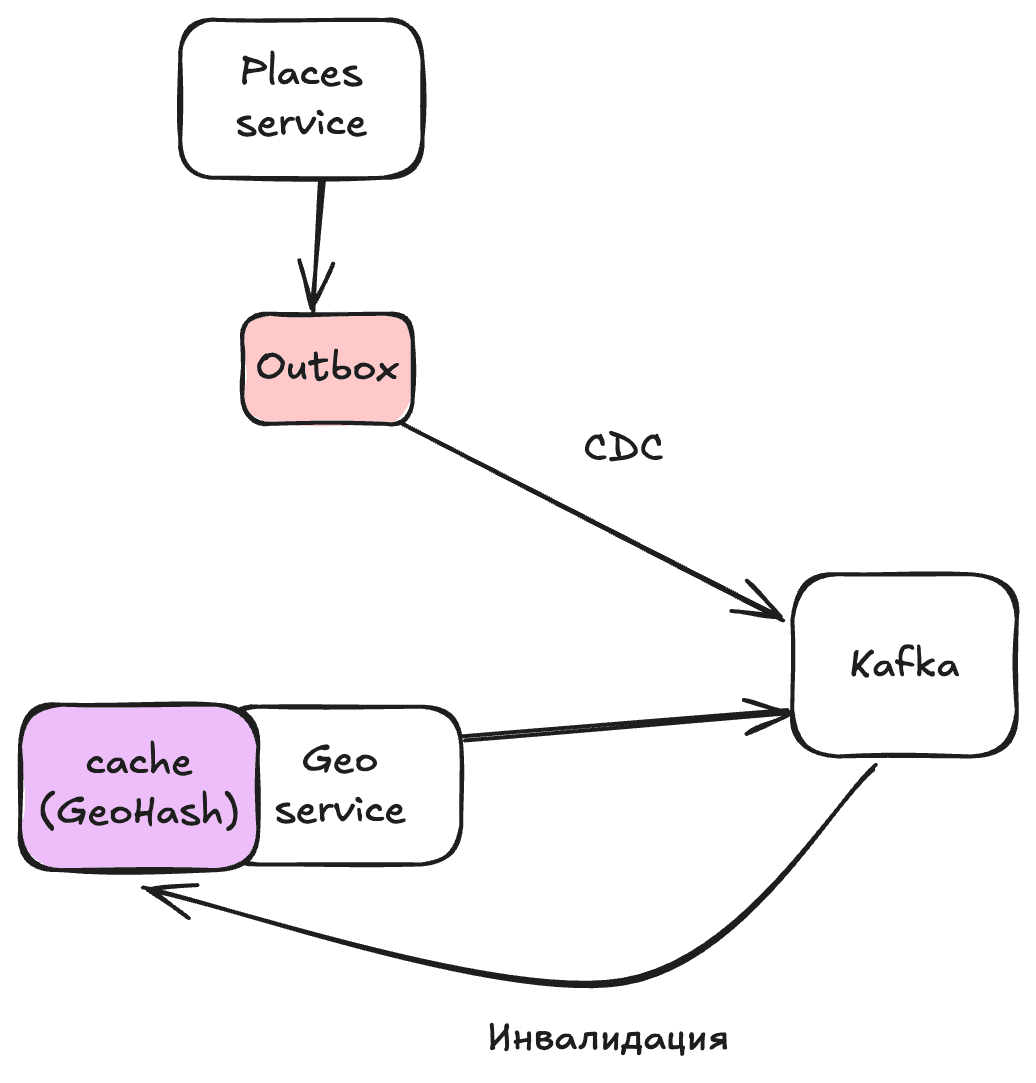
А также будет инвалидация через event-based:
Places Service → Outbox → Kafka → Geo Service Cache Invalidator
То есть после прихода данных из Kafka нужно проверить, есть ли данные в cache. И если есть, то удалить их.
Замещение
Будет через LRU, так как пользователи часто запрашивают а) популярные локации б) соседние локации.
Стратегия кеширования
❓ Если подзабыл, то можешь перечитать в теории Неделя 4 и также посмотреть след статейку: Nicolas FrankelA Hitchhiker's Guide to Caching Patterns: https://hazelcast.com/blog/a-hitchhikers-guide-to-caching-patterns/
TLDR: Cache-aside + write-around
Cache-aside оптимален для Geo Service по следующим причинам:
Характеристики геопространственных запросов:
- Unpredictable access patterns - невозможно предсказать какие области будут запрашиваться
- Read-heavy workload - 90% операций это поиск, не обновление
- Computation-intensive - пространственные запросы требуют значительных вычислений
Давай разберем пример:
- Geo Service ищет ключ
geo:dr5regw:1000:100 - Hit → возвращает кэш.
- Miss → делает запрос в Elasticsearch (BKD-tree), получает список id, кладёт результат в Redis с TTL = 1 ч, отдаёт клиенту.
Write-around означает, что при обновлении Places Service, данные НЕ записываются в Geo Service cache напрямую
- Spatial indexes rebuilding требует времени
- Cache pollution - новые данные могут быть не востребованы немедленно
Давай разберем пример:
- Places Service добавляет или изменяет координаты.
- Change-event попадает в Kafka; Geo Service:
- обновляет BKD-индекс;
- вычисляет список geohash-префиксов (dr5r, dr5re…) и удаляет соответствующие ключи в Redis.
- Данные не пишутся в кэш. При первом же чтении Cache-aside восстановит его.
И не забываем про backpressure
Тысячи пользователей одновременно ищут рестораны в центре Москвы
→ Massive cache miss rate для новых geohash ключей
→ Geo Service записывает тысячи cache entries одновременно → Redis memory overflow (OOM)
Как решаем:
- Adaptive Rate Limiting в Geo Service. Если нагрузка CPU достиагет X%, то перестаем обновлять кеш
- Memory-Aware Caching в Geo Service: перед тем, как писать, нужно проверить текущее состояние памяти в Redis
- Circuit Breaker: следим за кол-во ошибок от Redis
- На стороне Api Gateway, чтобы перенаправлять запросы в Geo Service & Elastic вместо Redis
- На стороне Geo Service, чтобы не писать в Redis
Cache warming
Так как кеш играет достаточно важную роль в нашей системе и может значительно улучшить UX пользователей — cache miss не самая лучшая вещь. Конечно, они будут случаться, но можно делать специальный background процесс, который раз в n времени будет обновлять топ-X заведений по определенным GeoHash индексам. Таким образом мы можем гарантировать более быструю отдачу заведений в популярной области.
Механизмы инвалидации, описанные выше, помогут нам держать кеш в актуальном состоянии.