Logging (логирование) в микросервисах — это процесс сбора и хранения информации о работе системы (ошибки, предупреждения, отладочная информация). Цель — быстро находить и устранять проблемы, понимать состояние системы «изнутри» и анализировать нетипичное поведение.
Виды логирования
- Application logs (логи приложения): Тексты ошибок, отладочные сообщения и бизнес-события внутри кода микросервиса. Часто пишутся не просто текстом, а в формате JSON. Они легко парсятся и невероятно удобны для поиска в инструментах вроде Kibana, Datadog или Grafana Loki.
- System logs (системные логи): Информация от операционной системы или инфраструктуры (например, OOMKilled в Docker/Kubernetes).
- Distributed tracing (распределённая трассировка): Метод, позволяющий отслеживать, как один запрос «путешествует» между десятком микросервисов (через TraceID). Подробнее мы разберем это в отдельном уроке.
Индустриальный стандарт: OpenTelemetry (OTel). Раньше логи, метрики и трейсы (три столпа Observability) собирались разными инструментами и библиотеками. Сейчас многие перешел на OpenTelemetry — единый открытый стандарт и SDK. Он позволяет твоему приложению собирать всю телеметрию в одном формате и отправлять куда угодно, не привязываясь к конкретному вендору.
Инфраструктура: Как собирать логи
Fluent Bit — это сверхлёгкий инструмент для сбора и отправки логов. Его часто ставят рядом с микросервисами или прямо внутри контейнеров, чтобы он:
- Подхватывал все логи из файлов и стандартных потоков вывода (stdout / stderr).
- Трансформировал их (например, фильтровал пароли или добавлял теги с названием сервера).
- Пачками (батчами) отправлял логи в центральное хранилище (Elasticsearch, Loki, S3).
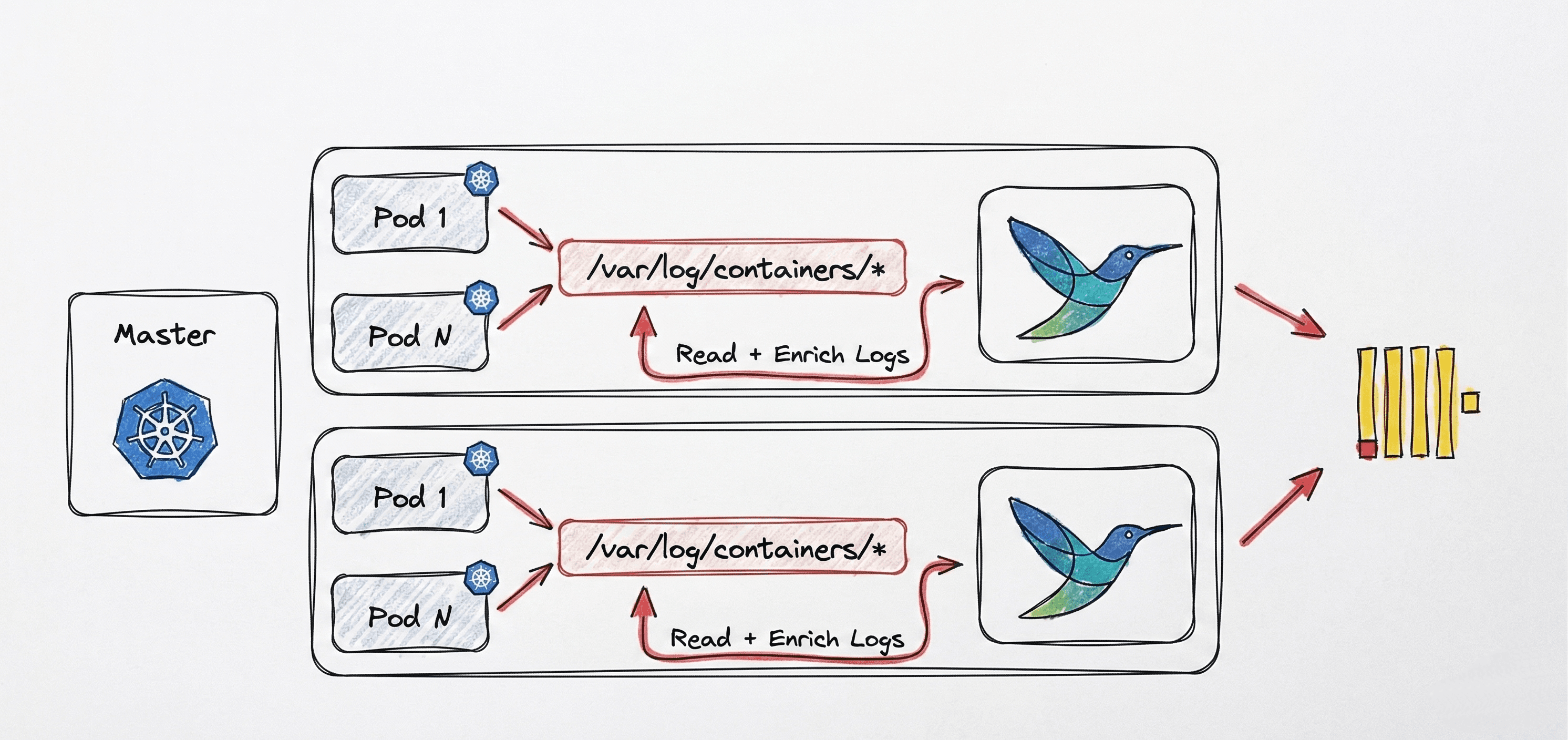
Как выглядит процесс:
- Твоя команда вообще не думает о доставке логов. Код просто пишет их в
stdout - Fluent Bit работает как невидимый агент-сборщик, берёт эти логи и по заданным DevOps-правилам пересылает дальше.
- В центральном хранилище удобно просматривать все события системы сотен микросервисов в одном поисковом окне.
Зачем всё это усложнять?
- Централизованное хранение: Когда у тебя 50 экземпляров одного сервиса, ты не сможешь заходить по SSH на каждый сервер, чтобы почитать логи. Тебе нужна единая точка.
- Мониторинг и алерты: Можно настроить уведомление: «Если слово FATAL появилось в логах авторизации больше 10 раз за минуту — буди дежурного».
- Упрощённая отладка: Скопировав TraceID из ошибки, ты можешь в один клик найти логи всех 5 сервисов, которые участвовали в этом сломанном бизнес-процессе.
Полезные ресурсы
- Опыт Pinterest (Агент Singer). Когда у тебя тысячи серверов, парсинг и пересылка логов может начать съедать CPU, который нужен для бизнес-логики. Читаем, как инженеры Pinterest написали сверхбыстрый агент Singer, чтобы надежно собирать петабайты логов без просадок серверов.
- Опыт Google (Система Monarch). Как мониторить сам мониторинг? Рассказ про глобальную систему Google Monarch, которая обрабатывает триллионы событий, оставаясь доступной даже при полном падении целых дата-центров.