Alerting (алертинг) — это система автоматических уведомлений. Вручную смотреть в дашборды Grafana 24/7 нереально. Как только метрики выходят за заданные пределы (всплеск 500-х ошибок, рост latency), система сама отправляет сигнал дежурной команде.
Главная цель: Узнать о проблеме и починить её до того, как пользователи начнут писать в поддержку.
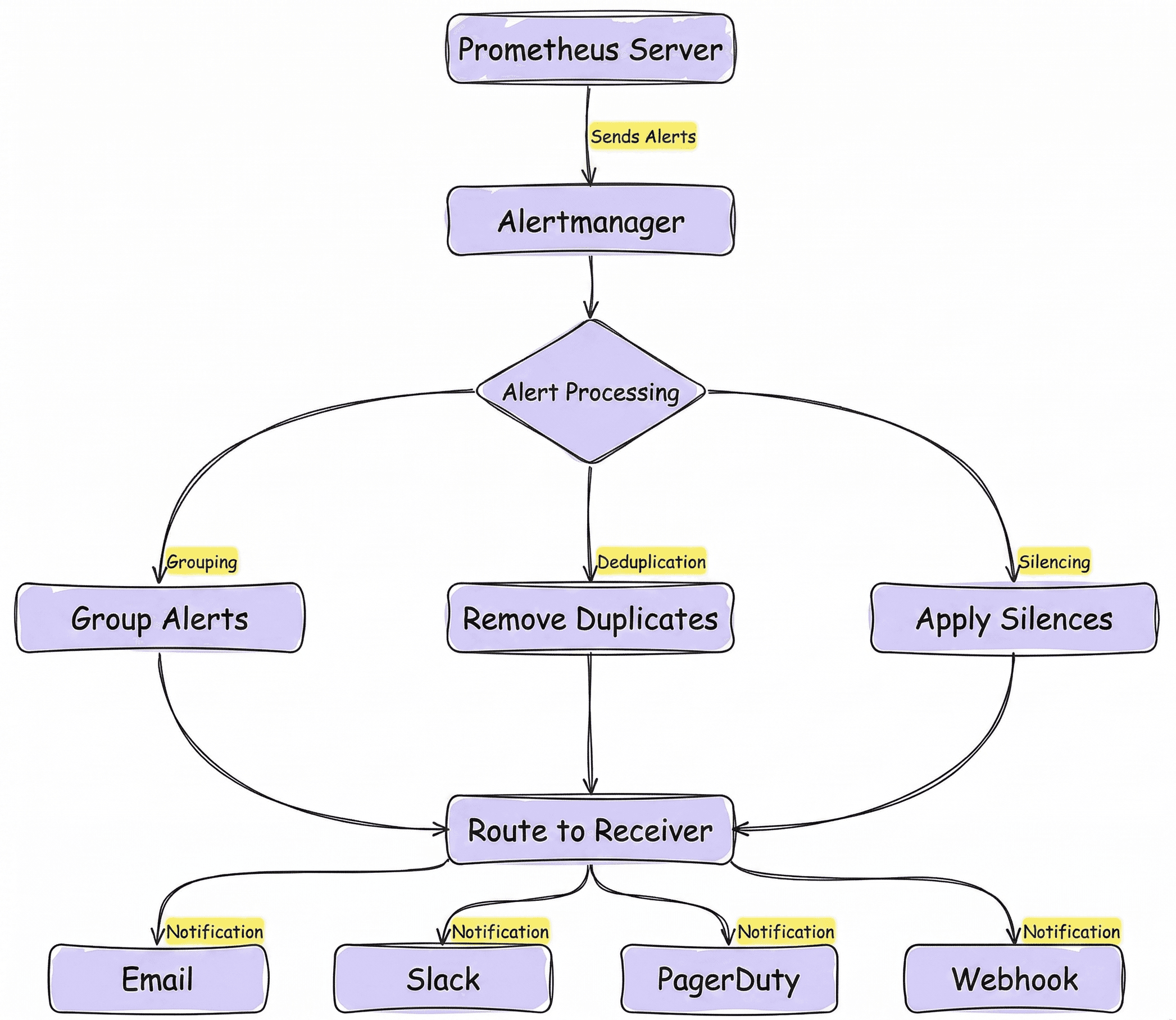
Инструменты: Кто поднимает тревогу?
- PromQL: Язык запросов Prometheus. Он ищет аномалии. Например, правило: «Если 5xx ошибок больше 10 за 5 минут — триггери алерт».
- Alertmanager: Компонент Prometheus, который берет сработавший триггер, убирает дубликаты (дедупликация) и маршрутизирует его. Мелкий баг — шлет в Slack. Полный отказ БД — инициирует звонок.
- PagerDuty / OpsGenie / Zabbix: Системы диспетчеризации. Они знают расписание дежурств разработчиков (on-call) и умеют делать «робозвонки» на телефон дежурному инженеру посреди ночи, пока тот не возьмет трубку.
Что именно мониторить? (RED & Golden Signals)
Не нужно вешать алерты на всё подряд. В индустрии есть два устоявшихся стандарта для веб-сервисов:
| RED Модель (Микросервисы) | Golden Signals (Google SRE) |
|---|---|
| R (Rate): Скорость запросов (RPS). | Traffic: Объем запросов к системе. |
| E (Errors): Процент ошибочных ответов. | Errors: Уровень ошибок (5xx). |
| D (Duration): Время обработки (Latency). | Latency: Время ответа на запрос. |
| Saturation (Насыщение): Насколько исчерпаны ресурсы (CPU, RAM, коннекты). |
Примеры PromQL-запросов для Golden Signals
1. Latency-алерт (Задержка): Если 95-й перцентиль времени ответа больше 300мс (0.3с) за последние 5 минут.
SQL
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket{job="myservice"}[5m])) > 0.3
2. Errors-алерт (Ошибки): Если 5xx-ошибок больше 10 штук за 5 минут.
SQL
rate(http_requests_total{job="myservice", code=~"5.."}[5m]) > 10
3. Saturation-алерт (Насыщение ресурсов): Если средняя загрузка CPU контейнера превышает 80% на протяжении 5 минут.
SQL
avg by (instance) (rate(process_cpu_seconds_total{job="myservice"}[5m])) > 0.80
Полезные ресурсы
- Smart Alerts от LinkedIn (ThirdEye). Алерты на основе жестких порогов быстро устаревают. Как LinkedIn использует машинное обучение (ML) в системе ThirdEye для поиска реальных аномалий в поведении пользователей.
- Uber Argos. Миллионы поездок в секунду. Как Uber построил Argos — систему алертинга в реальном времени, которая фильтрует шум и не генерирует ложных срабатываний, давая инженерам спокойно спать.