Ограничитель частоты запросов (в англ Rate Limiting) — это техника для ограничения количества запросов к нашей системе. Такой подход критически важен, потому что он помогает предотвратить DoS (Denial of Service) атаки. Иначе говоря, помогает избежать лишней нагрузки на систему, когда кто-то специально или случайно заваливает нашу систему запросами.
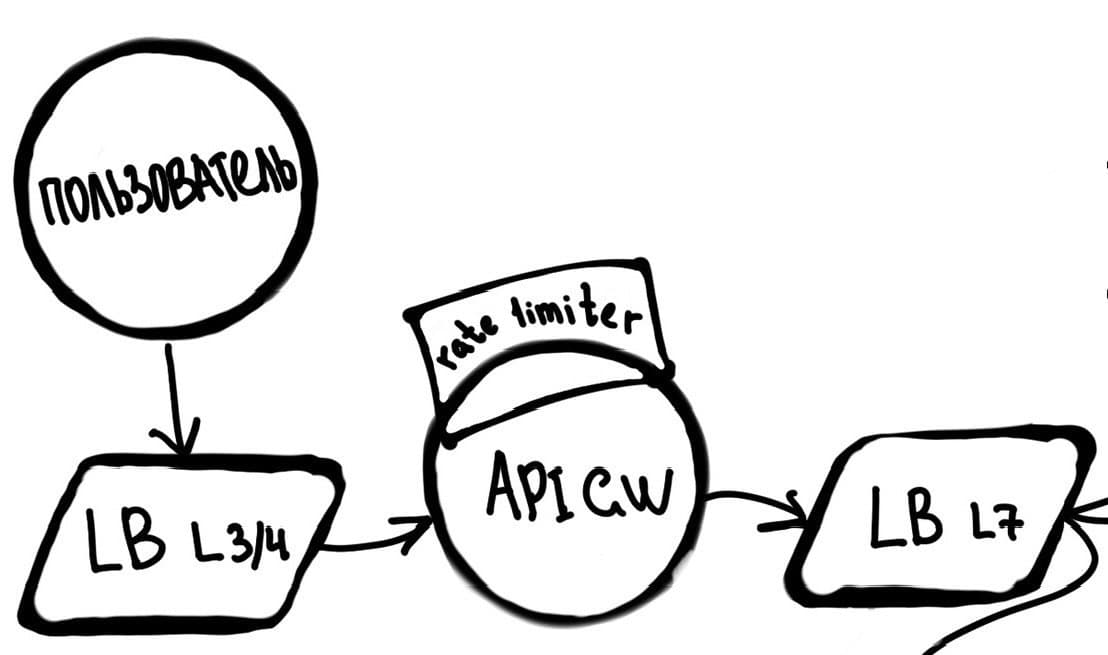
Rate limiter обычно ставится на Api Gw и LB. Почему именно туда: в микросервисах у нас много инстансов, и каждый инстанс, по сути, не знает ничего о другом. В таком случае нам нужно что-то, что будет стоять перед ними. И как раз Api Gw и LB — идеальные кандидаты для этого.
Золотое правило: Rate limiting можно использовать, когда клиенты могут сократить частоту опроса API, и это не сказывается негативно на их пользовательском опыте (UX).
Например, пользователь опрашивает ленту новостей в соцсети. Мы без ущерба для опыта клиента можем подрезать количество запросов в час или в минуту — вряд ли обычный клиент будет обновлять ленту новостей 10 раз за минуту. А вот какой-нибудь бот — легко. И такими ограничениями мы как раз защитим систему от этого бота.
А вот если мы перестараемся с ограничениями — например, оставим один запрос ленты в час — тут UX упадет. Так делать нельзя.
Сейчас мы с тобой ограничимся базовым принципом, который позволит твоей системе защититься от наплыва клиентов или ботов, но в то же время он достаточно интуитивен. Но помимо этого подхода есть, например, защита от конкурентных запросов и еще множество вариантов.
А еще рассмотрим алгоритм, который позволит выстроить механику допуска или блока клиента до нашей системы — token bucket. Он де-факто стандарт и в нашем случае его будет достаточно.
Requests Rate Limiter (Ограничитель Количества Запросов)
- Стандартное ограничение запросов к системе: N запросов в секунду, N запросов в минуту.
- При этом важно учитывать скачки (так называемые bursts) — кратковременное увеличение запросов к системе. Это позволяет пережить скачки нагрузки (spikes).
Token Bucket (пополнение токенов с фиксированной скоростью)

Алгоритм Token Bucket использует концепцию «ведра», в котором хранятся токены. Каждый токен даёт право на один запрос, а у ведра есть максимальная вместимость — максимальное количество токенов.
Токены добавляются в ведро с фиксированной скоростью. Когда приходит запрос, он может быть обработан, только если в ведре есть доступный токен. После обработки запроса токен удаляется из ведра. Если токенов нет, запрос отклоняется.
Основные характеристики:
- Гибкость — позволяет обрабатывать «всплески» (bursts) запросов, если токены накопились.
- Плавность — запросы обрабатываются с заданной средней скоростью.
Преимущества:
- Позволяет кратковременные всплески нагрузки.
- Простота реализации.
- Хорошо подходит для систем с переменной нагрузкой.
Недостатки:
- Требует аккуратного управления добавлением токенов.
- Может быть сложнее в распределённых системах.
Пару важных моментов: дальше по ходу недели в архитектуре у нас будет один Api Gw и один LB 7. Это сделано, чтобы не перегружать схему. На собесе ты можешь сказать точно также: «Api Gw раскидывает запросы по URL на разные L7, а L7 уже на каждый инстанс». Но здесь для простоты мы не будем так заморачиваться.