Супер, у нас с тобой уже есть очертания системы. Но не хватает одного из ключевых элементов — места для хранения данных. После прочтения следующего блока ты будешь знать, какие есть виды БД и в каком порядке нужно вносить улучшения в базу.
Для начала давай посмотрим на самые распространенные способы хранения данных.
- Row-Oriented (строчно-ориентированные) базы данных. В них используются OLTP-нагрузки (Online Transaction Processing). Такие БД подходят, когда нужно часто выполнять небольшие транзакции — например, регистрировать новых пользователей, оформлять заказы в интернет-магазине или вести учёт складских остатков. Примеры: PostgreSQL, MySQL, Oracle (в своём классическом виде).
- Key-value. Поиск идет по какому-то ключу, а все значения хранятся в произвольной структуре (int, JSON etc).
Есть другие форматы, но они в данном случае нам не нужны
Представь таблицу с гонщиками Формулы-1:
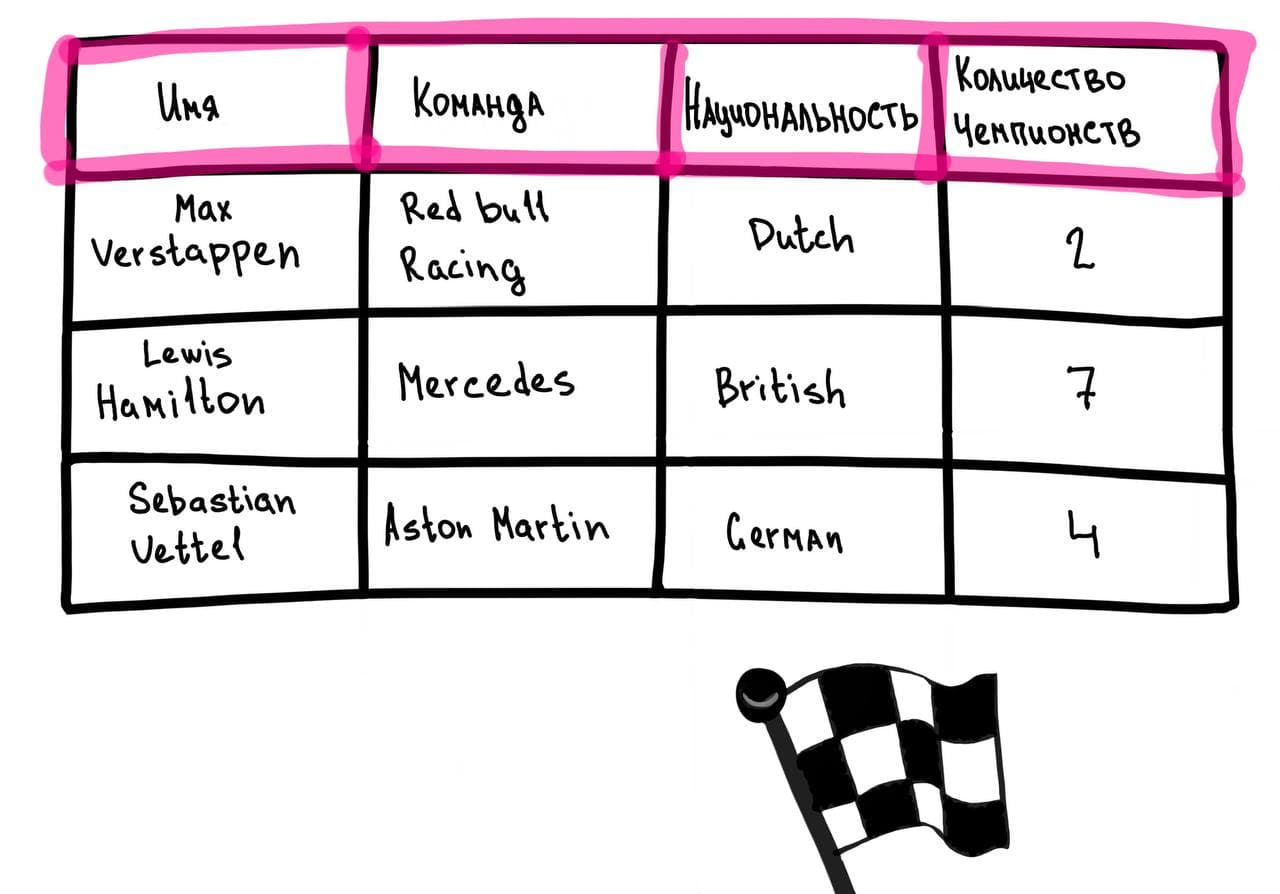
В строчно-ориентированном виде (Row-Oriented) эти данные записываются подряд по строкам:
- Max Verstappen, Red Bull Racing, Dutch, 2
- Lewis Hamilton, Mercedes, British, 7
- Sebastian Vettel, Aston Martin, German, 4
Давай посмотрим, какие в этом подходе есть преимущества и недостатки.
Плюсы:
- Если тебе нужно быстро читать или обновлять конкретную строку (например, данные по гонщику Максу Ферстаппену), весь нужный набор полей лежит рядом на диске → при работе с OLTP-нагрузками (регистрация пользователя, обновление адреса) это даёт быстрые операции чтения/записи.
Недостатки:
- Если нужно сделать полное сканирование по одному столбцу (например, найти все «национальности»), придётся пробегаться по всему набору данных, вычитывая при этом и ненужную информацию из других столбцов → это увеличивает время чтения и нагрузку на диск при аналитических запросах.
Теперь посмотрим, как это будет выглядеть в нашей системе.
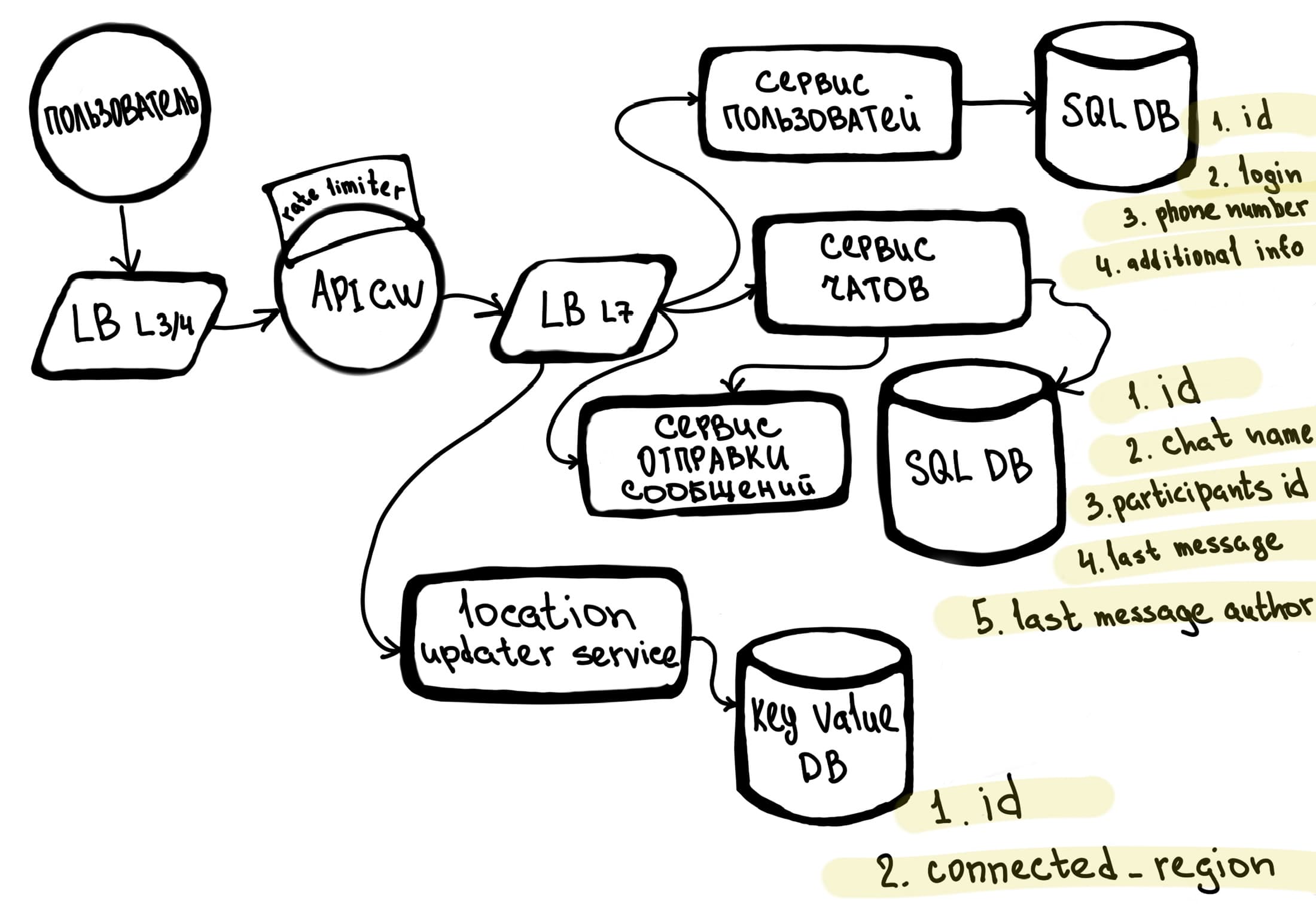
Давай, кстати, проговорим, какие новые блоки у нас тут появились:
1. SQL DB — БД для хранения (у нас для пользователя и для чатов).
2. Key-Value DB — БД для хранения локации пользователя.
Оптимизируем БД
Вот мы поставили базу, но она ненастроенная и под нагрузкой точно начнутся деградации скорости запросов.
Тут ты скажешь: «Я знаю шардирование». Но давай я тебя приторможу.
Прежде чем браться за добавление реплик или шардинг, обязательно проверь возможности оптимизации самой базы данных. Вот несколько советов, но подробнее всё это будем обсуждать дальше на курсе — кратко не рассказать.
- Правильная ли БД — если ты только начинаешь проект, проверь, подойдет ли твоя БД по хранению и нагрузке. Может быть, у тебя много связей и лучше реляционная БД, чем key-value. А может, у тебя аналитика, и тогда лучше всего колоночная БД.
- Правильные индексы — проверь, что ты навесил индексы на правильные поля. Например, ты делаешь запрос по полю A, B, C. Но индексы у тебя на полях A, B, D. И получается, что поля A, B используют индекс, а вот поле C сделает полное сканирование по оставшимся данным и не будет использовать индекс.
- Батчинг (то есть пакетная отправка) операций записи — лучше читать и писать в БД порциями. Так системе не придется открывать новое соединение каждый раз для каждого запроса.
- Анализ плана выполнения (execution plan) для самых тяжёлых SQL-запросов. Например, у PG есть EXPLAIN и EXPLAIN ANALYZE. Он позволяет понять, как идет процесс обработки твоего SQL запроса и где, возможно, БД не видит индекса или у нее другой затуп.
- Оптимизация структур таблиц и связей — точно ли таблицы разбиты правильно. Например, каждый JOIN увеличивает время обработки. Так что важно продумать, стоит ли дробить данные на несколько таблиц или их можно объединить.
- Pooling — эффективно ли твоя система использует соединения с БД или какие-то из них приходится открывать заново. Может быть, какие-то простаивают?
- Партицирование — то есть разбиение данных внутри одной БД.
- Шардирование — разбиение данных между разными инстансами БД.
Все эти штуки зачастую дают очень хороший прирост к производительности и могут отодвинуть необходимость более сложных решений.
Имей в виду, что последние два способа — партицирование и шардирование — самые сложные и требуют гораздо более тщательного анализа и подготовки. Не стоит бросаться в них, если не попробовал все шаги до этого. С большой долей вероятности поможет что-то другое, и они тебе окажутся не нужны.