Представь, что у тебя есть таблица с миллионом пользователей. Каждый раз, когда кто-то логинится, тебе нужно найти его по email. Без индексов базе данных пришлось бы просканировать всю таблицу от начала до конца (Full Scan). Это как искать нужное слово в библиотеке, перелистывая все страницы каждой книги подряд.
Именно поэтому современные БД используют индексы — специальные структуры данных, которые работают как алфавитный указатель. И стандартом здесь являются B-деревья (B-Tree).
Но чтобы понять, как устроены B-деревья, нам нужно спуститься на уровень физики — к устройству жесткого диска.
Физика диска и Страницы памяти (Pages)
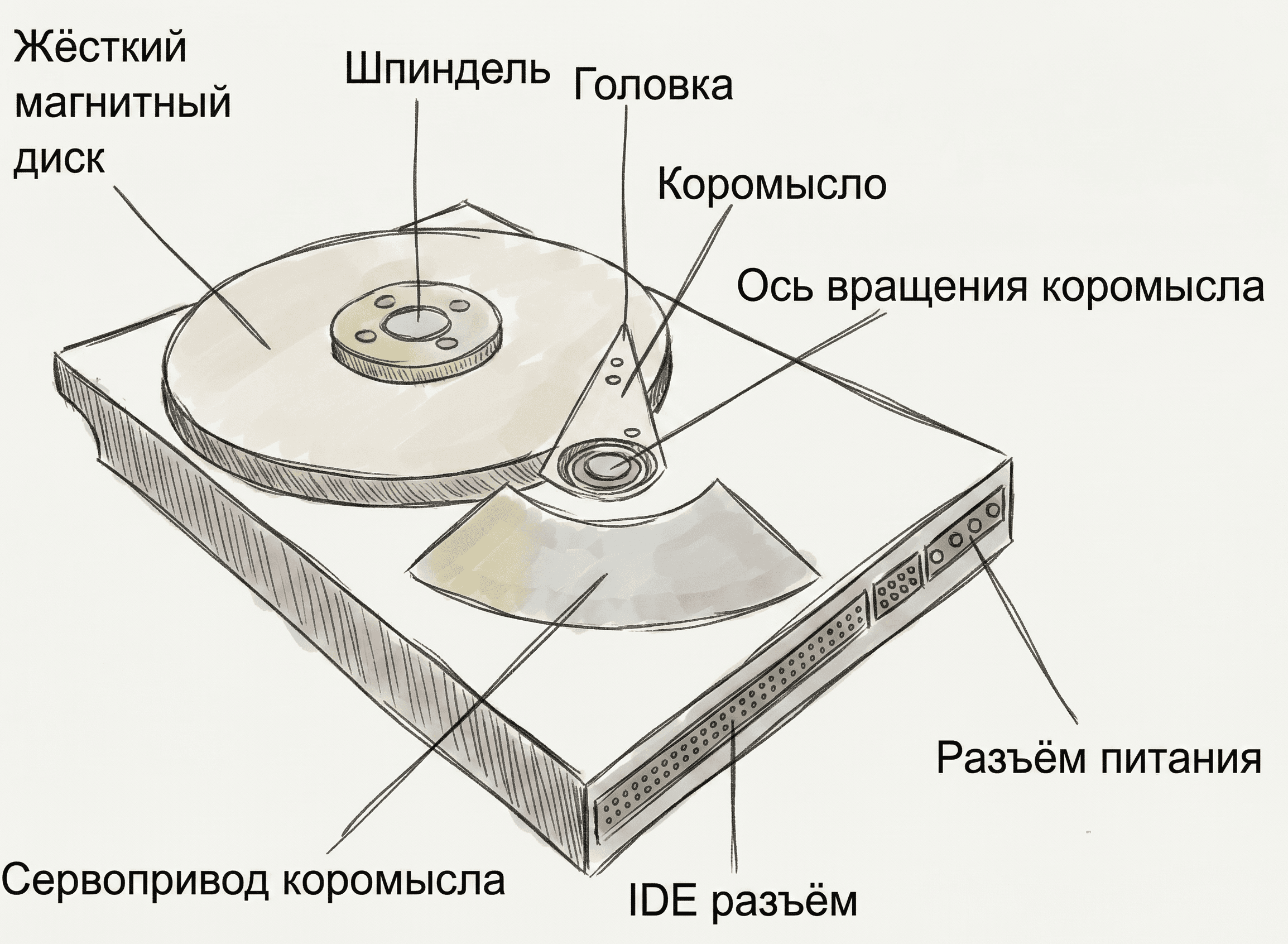
Скорость доступа к диску кардинально (в тысячи раз) отличается от скорости работы с оперативной памятью (RAM). Классический жесткий диск (HDD) — это механическое устройство. Он состоит из:
- Пластин (platters) — физических магнитных дисков;
- Треков (tracks) — концентрических кругов на пластине;
- Секторов (sectors) — мельчайших физических единиц хранения (обычно 512 байт).
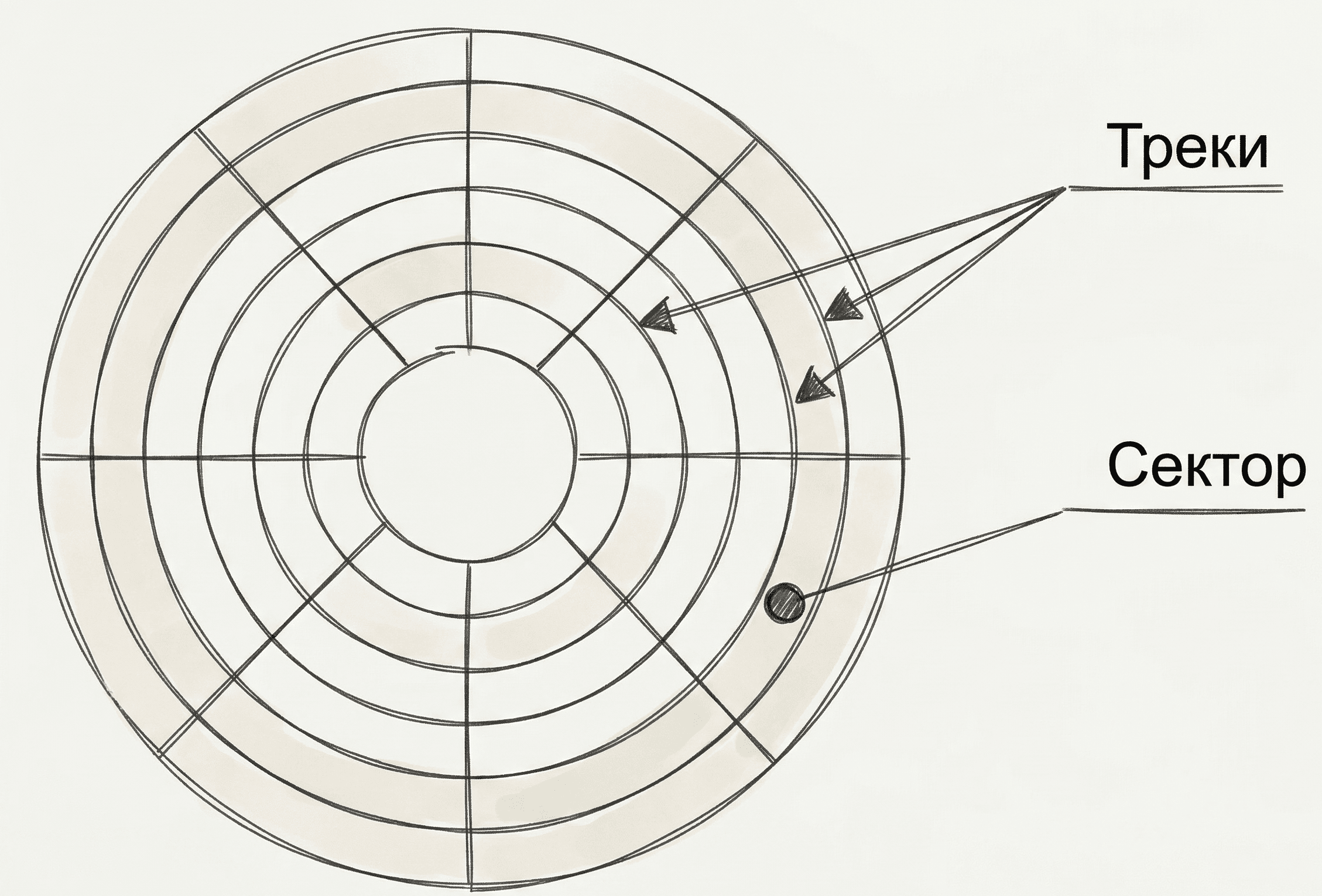
Главное правило I/O: Операционная система и СУБД никогда не читают данные по одному байту. Каждое обращение к диску заставляет считывающую головку физически двигаться (Random I/O), что очень медленно. Поэтому данные всегда читаются кусками — страницами (Pages) или блоками. Стандартный размер страницы — 4 КБ или 8 КБ.
Даже если тебе нужен всего один байт, база данных поднимет с диска в память всю страницу на 4 КБ. А значит, мы должны спроектировать структуру данных так, чтобы она идеально помещалась в эти 4 КБ и приносила максимум пользы за одно чтение.
Идея B-Tree: Идеальная структура под диск
B-дерево (B-Tree) хранит пары ключ-значение. Ключ — это то, по чему мы ищем (например, email), а значение — это указатель на физический адрес строки на диске.
Обычные бинарные деревья (где у узла только 2 потомка) растут глубоко вниз. Искать в них пришлось бы долго: каждый шаг вниз — это чтение новой страницы с диска. Поэтому B-деревья делают n-арными (широкими и плоскими). Каждый узел может иметь сотни потомков.

Размер страницы и производительность
Вся магия B-Tree в том, что размер одного его узла подгоняется ровно под размер страницы диска (те самые 4–8 КБ).
- За одно физическое чтение с диска мы получаем не 2 ссылки (как в бинарном дереве), а целый массив ключей.
- Чем больше ключей помещается в один узел, тем шире дерево и тем меньше его глубина (уровни).
- Меньше уровней = меньше прыжков по диску = феноменально быстрый поиск.
В PostgreSQL один узел B-дерева может вместить около 300 ссылок (зависит от размера ключа). Это означает, что для таблицы в 10 миллионов записей дереву понадобится всего 3-4 уровня в глубину. То есть, чтобы найти любую из 10 млн строк, базе потребуется сделать всего 3-4 чтения с диска!