Мы уже знаем, что B-дерево помогает быстро найти запись по ключу. Но в реальных базах данных есть огромная проблема, на которой «чистое» B-дерево ломается. И эта проблема — диапазонные запросы (Range Queries).
Слабое место классического B-Tree
В классическом B-дереве данные (указатели на строки) разбросаны по всем уровням. Представь, что тебе нужно найти пользователей с ID от 10 до 100.
- Сначала ты находишь ID 10 (спуск от корня).
- Чтобы найти ID 11, тебе, скорее всего, придется снова подниматься к родителю и спускаться в другой узел.
- Для каждой записи в диапазоне ты «прыгаешь» вверх-вниз по дереву. Каждый такой прыжок — это новое случайное чтение с диска.
Результат: поиск по диапазону превращается в хаос из дисковых операций. Инженерам нужно было решение, которое позволит «прочитать один раз и просто листать дальше».
Решение: B+ Tree (Современный стандарт)
Когда в документации MySQL или PostgreSQL пишут «B-Tree индекс», на 99% там подразумевается именно B+ дерево. Оно вводит два радикальных изменения:
- Данные — только в листьях: Верхние узлы больше не хранят указатели на строки таблицы. Они хранят только ключи-навигаторы («тебе направо» или «тебе налево»). Это позволяет запихнуть еще больше ключей в одну страницу, делая дерево еще плотнее.
- Связный список внизу: Все листовые узлы (нижний уровень) связаны друг с другом указателями
nextprev
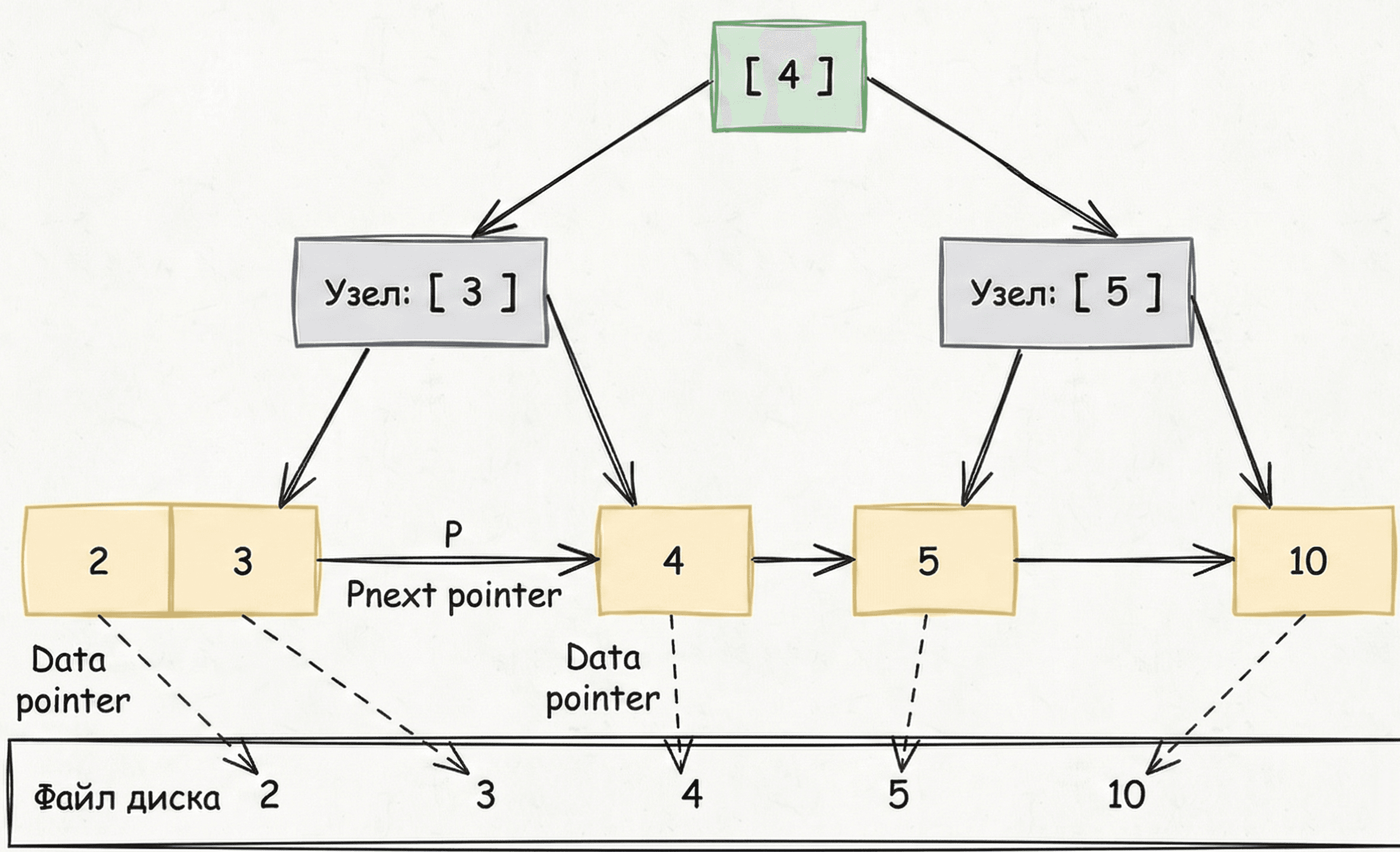
Как работает операция READ в B+ Tree
Алгоритм поиска теперь всегда одинаково эффективен:
- Точечный поиск (ID=123): Мы всегда спускаемся до самого нижнего уровня. Да, мы никогда не найдем данные на верхних ярусах (как могли в B-Tree), но за счет плотности узлов этот спуск гарантированно занимает всего 3-4 шага.
- Поиск по диапазону (ID от 10 до 100): Мы спускаемся один раз к ID 10. А дальше мы просто «скользим» вправо по связному списку листьев, читая данные подряд, пока не дойдем до 100. Это последовательное чтение — самое быстрое, что умеет диск.
Почему это круто: В PostgreSQL для таблицы с миллионом строк глубина B+ дерева обычно составляет всего 3 уровня. Поиск любой записи — это ровно 3 операции чтения. А поиск тысячи записей подряд — это 3 операции спуска + пара последовательных чтений соседних страниц.